深度学习中的数学基础笔记
挺火的一个概念,选了一节公选课上,不过最后也就学了个皮毛。截图是来自 3Blue1Brown 数学频道,以文字识别为例
神经网络的架构
- 神经元:神经元就相当于一个函数,输入以上一层为输入,输出给下一层。在文字识别中,一个神经元就是一个文字图像中一个像素的颜色深浅。这些深浅不一的像素(神经元)就组成了我们的文字。
- 在神经网络中,神经元将自己的数据一层一层的传递,最后得到了最终的结果。例如文字识别中,第一层识别小的笔画,然后将自己的数据传递给下一层,然后再识别大的笔画,最终识别出来的文字
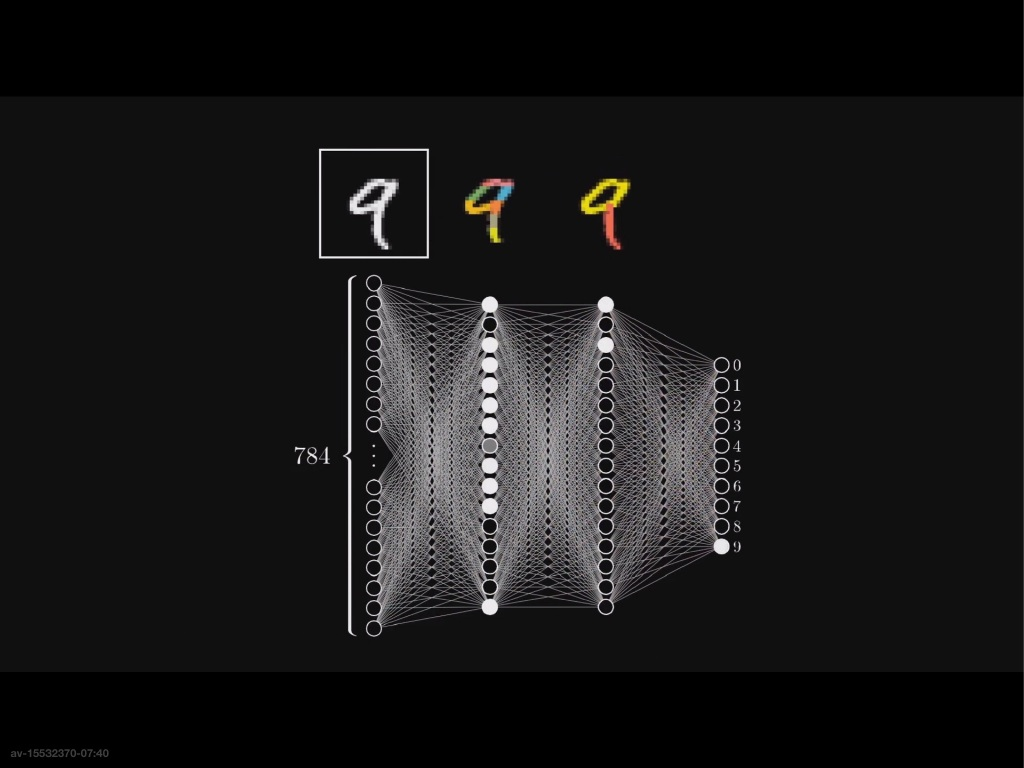
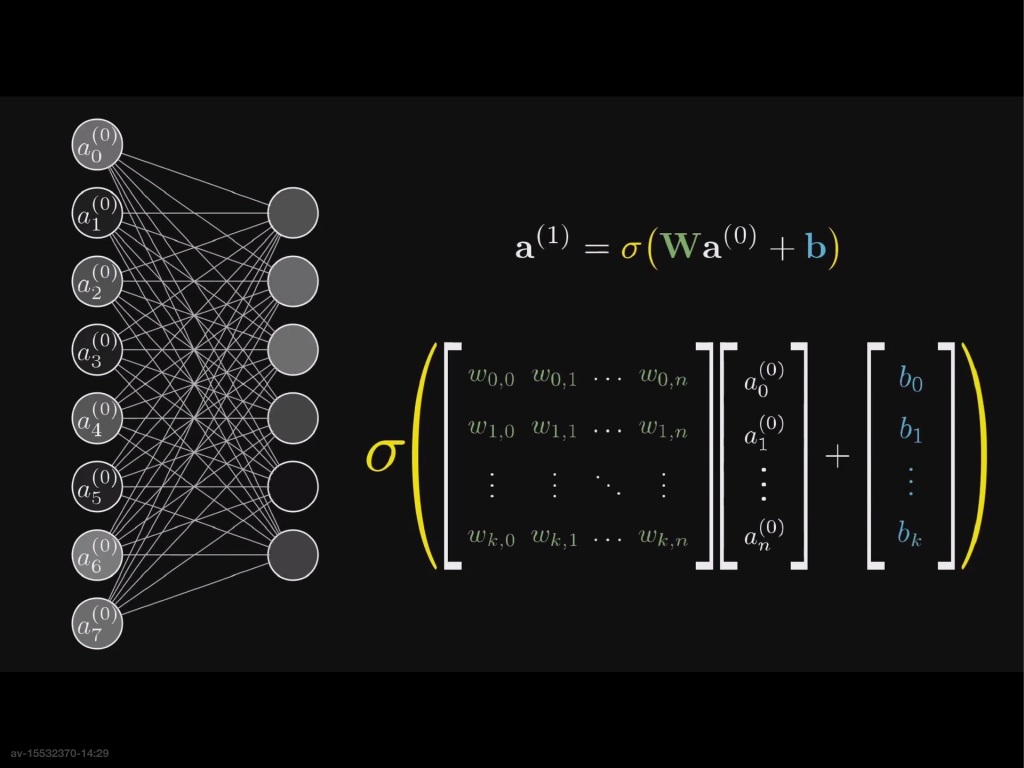
识别的过程:以第二层的神经元为例,第一层的一个神经元要想识别小笔画,就必须要对第一层的每一个数据$a$,赋予一个权重$w$(表示第一层的那个神经元对这个地方的敏感程度)然后求和,得到这个神经元所代表的的数值
在实际情况中需要这个值在 0~1 之间,因此需要给它将这个数据减去加上一个函数(比如Sigmoid函数)
不过,$w_1a_1+w_2a_2+…+w_na_n$ 的出来可以是任何数,直接用上面的公式表示会出现过早激发的现象,因此需要减去一个偏置值$b$
这样的话就得到了第二层神经元的数据,以此类推,可以得到最终结果。
用向量表示,可以得到下面的($a^{(0)}$ 为第0层神经元的数值(激活值))
梯度下降法
上面我们得到了那个可以计算激活值的递推方程,但是一开始的时候,上面所有的系数都是随机的,因此此时得到的结果误差会非常大。梯度下降算法能够使得这些系数得到的偏差最小。为了表示这个偏差,引出代价函数的概念,下面是一种常见的代价函数
我们的目标就是使得这个函数的值最小。而沿着这个函数的负梯度方向走,这个函数的函数值就下降的越快,因此让这个函数变小的算法就出来了:
1 | |
相关的数学公式为
反向传播算法
反向传播算法的核心就是计算上面提到的梯度 $\bigtriangledown C$
先考虑两个神经元之间的传播。
记第一个神经元的所有参数上角标为$(L-1)$,下角标为$L$ .
因此有以下参数:
- $a^{(L-1)},a^{(L)}$ 两个神经元的激活值
- $w^{(L)},b^{(L)}$ 从(L-1)层到(L)层的权重
- $y^{(L)}$ 想要达到的激活值
为了计算的方便,记 $z^{(L)}=w^{(L)}a^{(L-1)}+b^{(L)}$,则有
由$a^{(L-1)}$到$a^{(L)}$ 的计算的过程是
1 | |
而要求的是
根据上面的方程可以得到
同理
将这个简单的两个神经元之间的传播扩展到一般情况
其中,i是上层的第i个神经元;j为下层的第j个神经元
实际举例
构建一个四层的BP人工神经网络,不少于16个神经元结点,自定义一个样本,模拟计算一次完整的样本训练过程,整个过程必须包括各个神经元结点的输入值、输出值以及反馈过程中对权向量的修改情况。
构建的网络
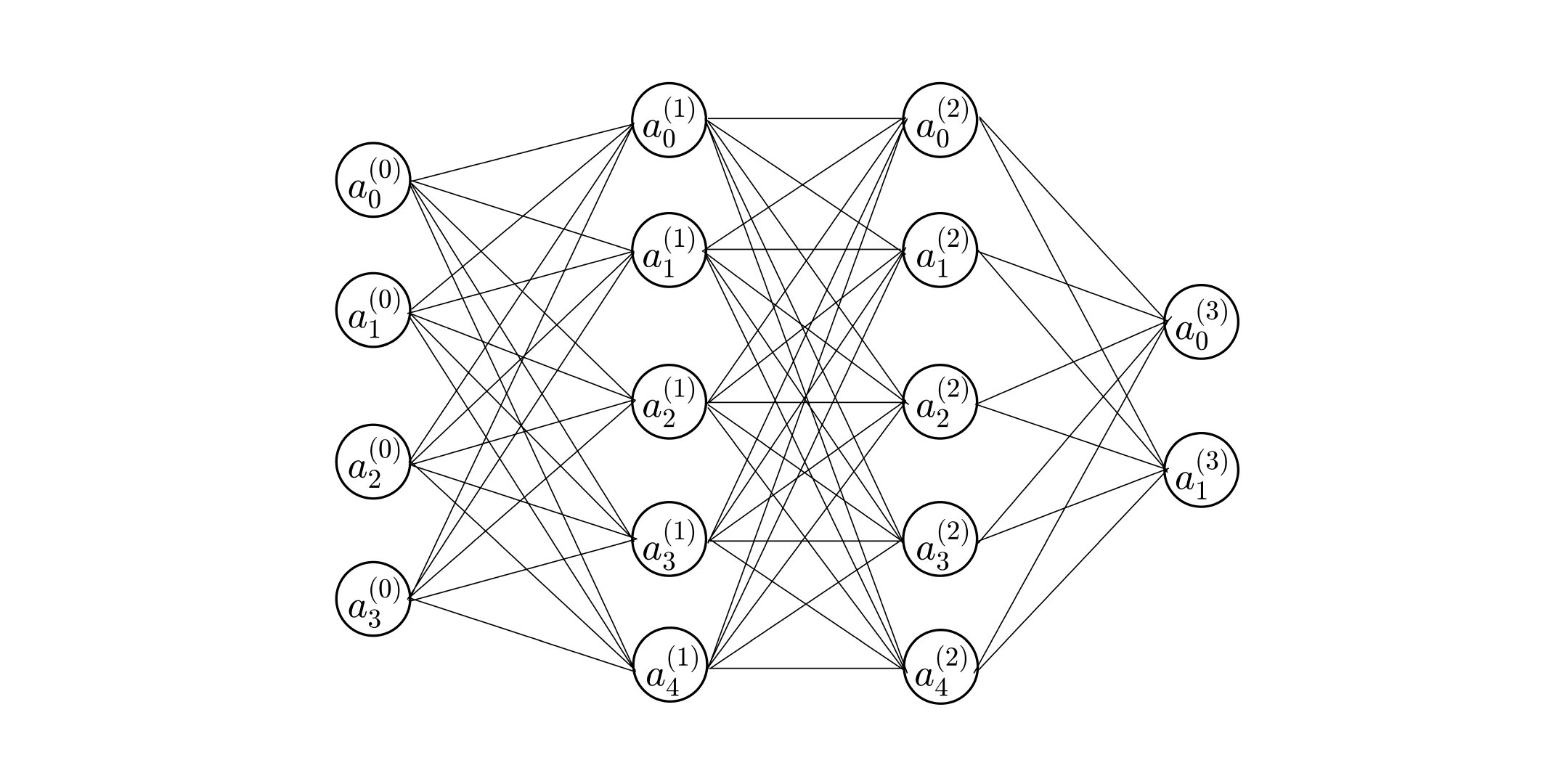
其中:
- 输入层 $a^{(0)}=\left[4\ 3\ 2\ 1 \right]^T$
- 权重 $w^{(1)}=\left[
\begin{matrix}
0.01 & 0.06 & 0.11 & 0.16\\
0.02 & 0.07 & 0.12 & 0.17\\
0.03 & 0.08 & 0.13 & 0.18\\
0.04 & 0.09 & 0.14 & 0.19\\
0.05 & 0.10 & 0.15 & 0.20\\
\end{matrix}
\right],w^{(2)}=\left[
\begin{matrix}0.21 & 0.22 & 0.23 &0.24 & 0.25\\
0.16 & 0.17 & 0.18 &0.19 & 0.20\\
0.11 & 0.12 & 0.13 &0.14 & 0.15\\
0.06 & 0.07 & 0.08 & 0.09 & 0.10\\
0.01 & 0.02 & 0.03 & 0.04 & 0.05\\\end{matrix}
\right],w^{(3)}=\left[
\begin{matrix}
0.16 & 0.21 \\0.17 & 0.22 \\ 0.18 &0.23\\0.19 & 0.24\\0.20 & 0.25\\
\end{matrix}
\right]^T$ - 期望输出层 $y^{(3)}=[0.10\ 0.24]^T$
- 每个节点没有偏置
- 节点激活函数 $\sigma(x)=1/{(1+e^{-x})}$,导数$\sigma’(x)=\sigma(x)(1-\sigma(x))$
符号说明
- $a_i^{(L)}$:第 (L) 层节点的第 i 个元素的 输出值
- $z_i^{(L)}$:第 (L) 层节点的第 i 个元素的 输入值
- $w_{ij}^{(L)}$:第 (L-1) 层 的第 i 个节点 到 第 (L) 层 的第 j 个节点的 权重
正向传播
0层→1层
第一层输入值为:
第一层输出值为:
1层→2层
第二层输入值为:
第二层输出值为:
2层→3层
第三层输入值为:
第三层输出值为:
误差
反向传播
3层→2层
有以下数学关系:
因此 权重梯度
修正后权重:
2层→1层
有以下数学关系:
因此 权重梯度
其中
修正后权重:
1层→0层
有以下数学关系:
因此 权重梯度
其中
修正后权重:
一次完整的样本训练过程就结束了
训练后误差
计算过程
Matlab代码,比较低级,算是半个手工计算。。。
1 | |
2018-10-21