计算机网络
计算机网络的笔记和总结,方便日后回顾用
概述
基本概念
因特网
网络是节点和边,计算机网络就是以计算机为节点的网络。因特网就是全球节点数量最多,覆盖范围最大的一个计算机网络。
节点就是主机和路由器交换机
边就是通信链路。通信链路有接入链路(与主机相连)和主干链路。
主机包括个人电脑、手机、平板物联网系统,还有公司的服务器等等
因特网是一个非常复杂的网络,它有两种解读方式。
从组成来看,因特网是由网络边缘、网络核心和接入网构成的
从功能来看,因特网是分布式应用进程和为分布式进程提供服务的基础设施
分布式应用进程就是各种需要网络的软件
协议
对等通信实体之间交换的报文的规范的集合(包括语法、语义、时序等)
因特网的组成
网络可以分为网络边缘(就是主机)和网络核心,还有接入网
网络边缘就是主机,网络核心是网络中的交换节点,通讯链路将网络边缘接入网络核心
主机和端系统是同一个东西
网络边缘
网络的边缘就是一堆主机。这些主机的通讯有两种模式,它们的通讯也有两种服务
根据主机(应用)之间通讯的模式,可以分为
这里的模式是主机和主机之间的通讯,不考虑网络核心和接入网的内容。
- C/S 模式:就是客户端/服务器模式。这里向服务器发出指令的就是客户端,接受指令并返还数据给客户端的就是服务器。一般一台服务器需要服务很多客户端。这种模式的弊端就是可拓展性差,当服务器不够时,需要耗费很高的成本来更新。
- P2P模式:就是对等模式,P2P模式没有服务器,或服务器非常少。这里的主机既是服务器,又是客户端,各自为各自提供服务。
根据网络其他部分为它提供的服务,可以分为
- 面向连接的服务(TCP服务):数据传输之前要先握手,同时保证数据传输的可靠有序,同时提供流量控制和拥塞控制的服务
- 无连接的服务(UDP服务):数据传输不需要握手,直接传,不保证数据一定到达。适用于流媒体等的应用程序
接入网
接入网就是把主机连入网络核心。
接入方式
网络的接入方式有以下几种
住宅接入
- DSL ( Digital Subscriber Line ), ADSL:电话线用来当网线
- 电缆接入 ( cable Internet access ):电视线当网线
- FTTH ( Fiber To The Home )光纤入户
企业接入
- 以太网 ( Ethernet )
- 无线接入
- 无线局域网 (LAN):WiFi
- 广域无线接入:4G,5G
物理媒体
- 引导型媒体:双绞铜线(电话线),同轴电缆(电视),光纤
- 非引导型媒体:微波、LAN (WiFi)、广域 (蜂窝数据)、卫星
网络核心
网络的核心就是链路、路由器和交换机的地盘了。
这一块的核心就是数据的传输。有两种传输方式
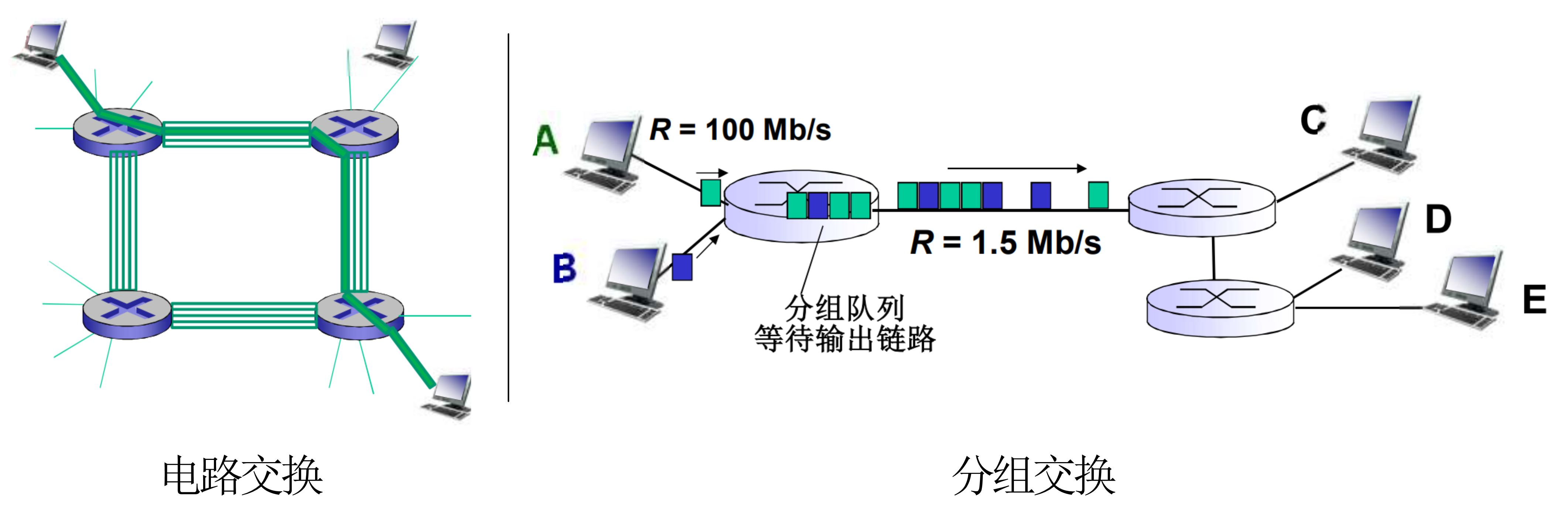
电路交换
把链路划分成一份一份的(按照原理不同可以分为 时分(TDM)、频分(FDM)和波分 )。进行数据传输时,建立起一条从源主机到目标主机连接,同时这个连接独占所经过的链路的其中一份。
这种方式常被电话网络使用。连接独占资源,有性能保障。
电路交换并不适合于计算机网络。因为计算机网络具有突发性,比较浪费,同时建立连接的时间比较久
分组交换
把传输的数据分成一组一组的。传输的时候每个数据组单独传输,独占这条链路的所有资源,同时路由器会把数据组存储起来,等数据组传输完毕后再转发到下一个路由器,最终一个个分组被传输到目标主机。
分组交换有两个关键功能:路由和转发
- 路由:决定分组采用的源到目标的路径
- 转发:将分组从路由器的输 入链路转移到输出链路
分组交换也有两种方式:数据报(分组的目标地址决定下一跳,在不同的阶段,路由可以改变)和虚电路(在呼叫建立时决定路径,在整个呼叫中路径保持不变。每个分组都带标签,标签决定下一跳)
路由器存储的目的时为了实现资源的共用。不存储的话,就相当于直接独占了整个链路。
线路交换能够实现多路复用,提高资源利用率,容纳更多的应用
因特网的结构
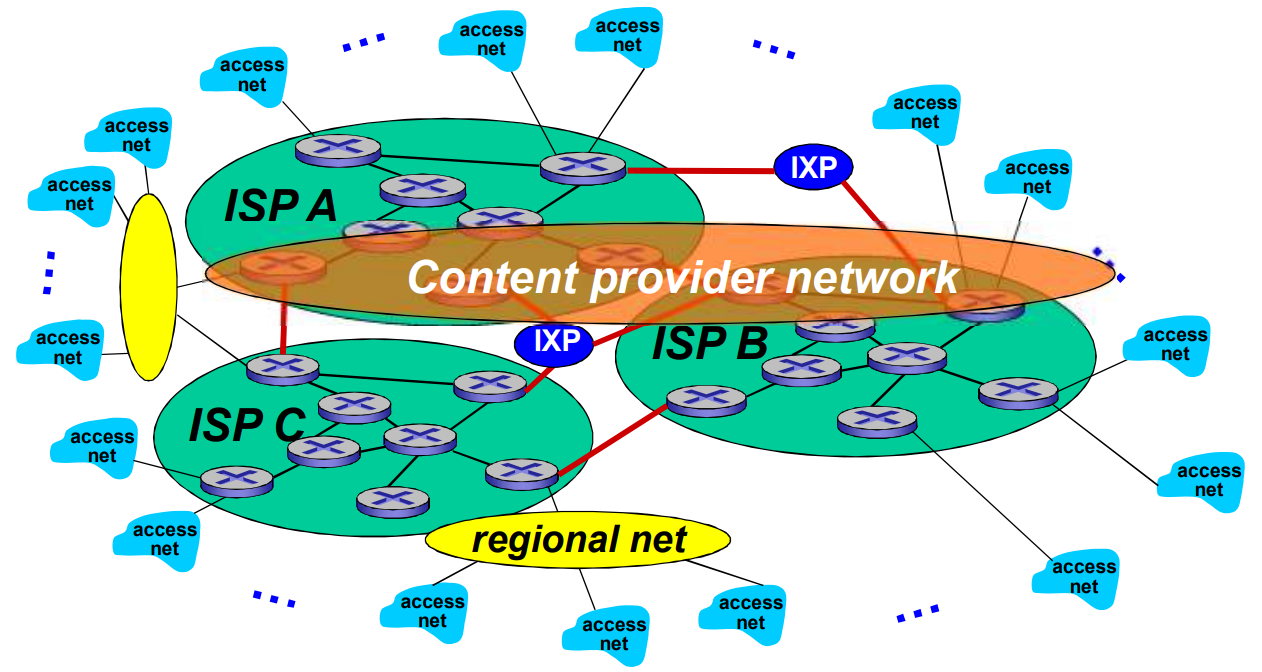
松散的层次结构
- 各个接入ISP 接入一个全球 ISP
- 有多个全球 ISP相互竞争又相互连接(通过IXP连接)
- 业务进行细分,出现区域ISP
- 内容提供商 (ICP) 建立自己的网络
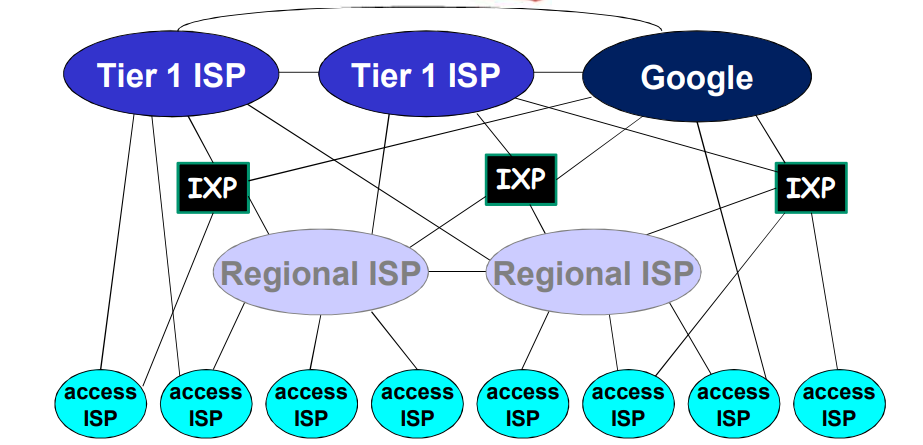
ISP之间的连接:对等连接、IXP
因特网的实现
这一块是最关键的。
复杂的功能通过分层来实现。总共有 5 层:
分层实现结构清晰,易于维护和升级,但是效率低。
| 名称 | 作用 | 例子 | 数据单元 |
|---|---|---|---|
| 应用层 | 网络应用 | HTTP, FTP | 报文 Message |
| 传输层 | 主机之间的数据传输,区分进程 | TCP, UDP | 报文段 Segment (TCP : 段,UDP: 数据报) |
| 网络层 | 为数据报从源到目的选择路由(端对端通信) | IP, 路由协议 | 分组 Packet |
| 链路层 | 相邻网络节点间的数据传输(点对点通信) | 以太网, WiFi | 帧 Frame |
| 物理层 | 在线路上传送bit | 位 Bit |
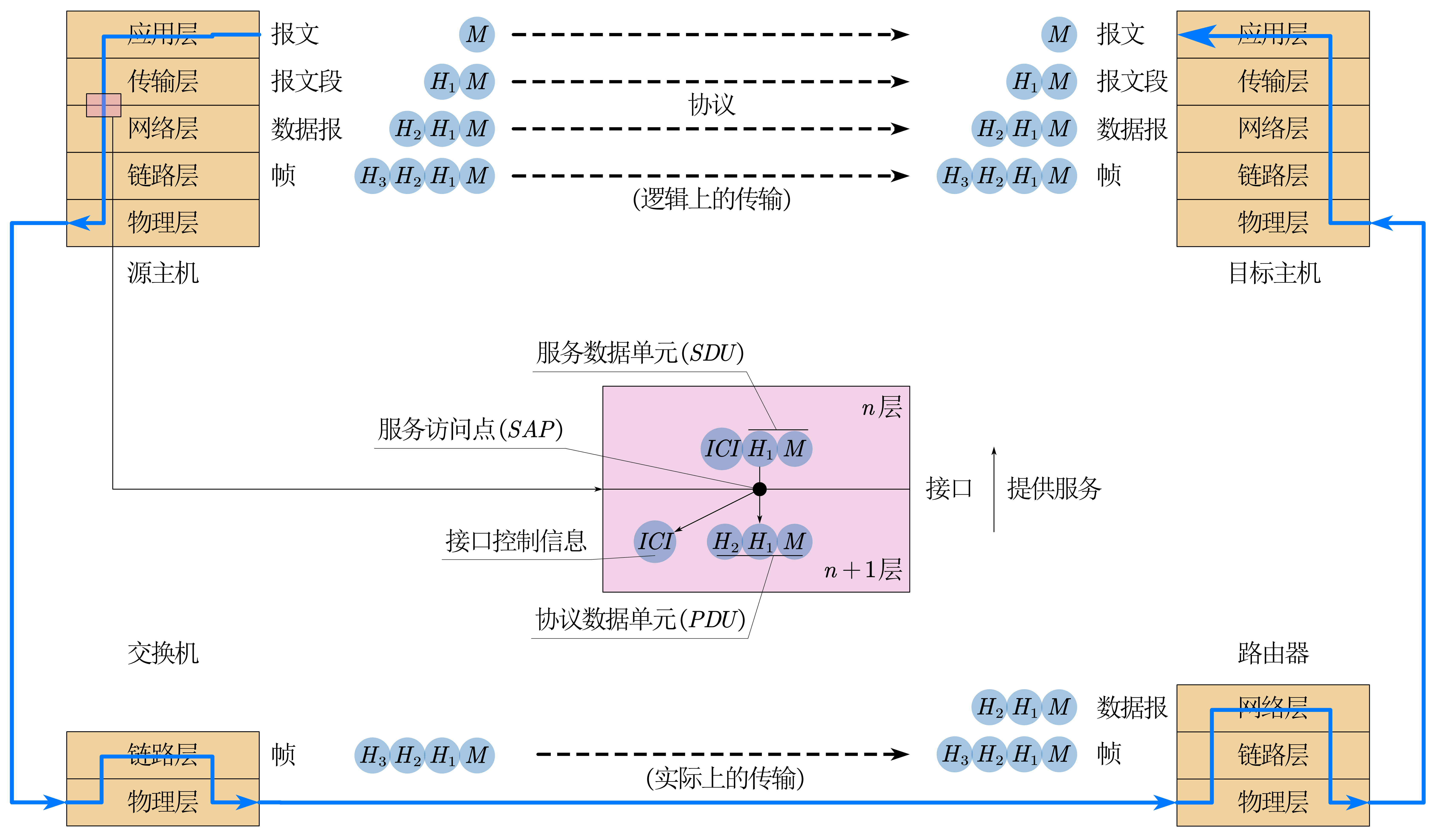
每层通过层间接口访问下层服务获取报文,从而为上层提供服务,最终实现复杂功能。
服务(Service):低层实体向上层实体提供它们之间的通信的能力,是通过原语(primitive)来操作的
服务有两种类型:面向连接的服务(事先要建立连接,通信结束后去除连接)和无连接的服务
上层使用下层提供的服务通过层间的接口,这个接口叫做服务访问点
协议(protocol) :对等层实体(peer entity)之间在相互通信的过程中,需要遵循的规则的集合
本层协议的实现要靠下层提供的服务来实现,本层实体通过协议为上层提供更高级的服务
各层传输时,对加上本层的信息,对数据进行封装和解封装
封装和解封装的过程
- 第 n 层要往第 n + 1 层发送的数据包括这一层的头和上一层的数据单元,这个数据叫做服务数据单元(SDU)。往下层发的时候,不光要发SDU,还要发送一些接口控制信息(ICI)(类似于n + 1层采用什么样的协议这些的)。
- ICI 和 SDU 在服务访问点把数据传递给 n + 1 层(SAP可以当作是一些函数)。
- n + 1 层拿到数据后把 ICI 和 SDU 分开,并且把SDU重新整合(分组或者合并)载加上自己的头,就形成了协议数据单元(PDU)。当 n + 1 层向下传递时,PDU就变成了SDU(本层的PDU为下层的SDU,本层的SDU为上层的PDU)
因特网的性能
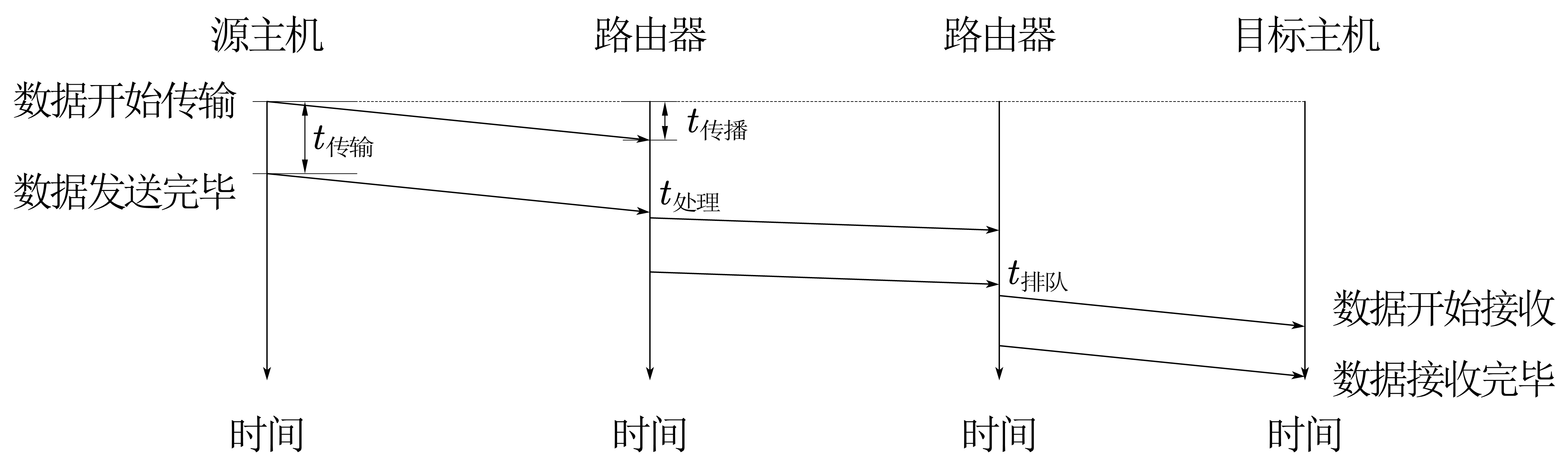
- 延时:有四种延时
- 传播延时:当两台主机距离过长的时候,就要考虑光的传播速度了
- 传输延时:数据在网线中传播要考虑网线的带宽
- 处理延时:路由器存储转发过程中的处理的时间
- 排队延时:当路由器正在发的时刻,数据又来了,新的数据就需要排队等待路由器发完
- 流量强度 $L\alpha/R$:
- 吞吐量
- 丢失
- 缓冲区溢出
- 出错抛弃
应用层
应用层是网络存在的理由。应用层的特点是协议很多,比较重要的有HTTP,SMTP等等,然后DNS也是运行在应用层当中的。
应用层协议原理
网络应用的体系架构
应用层有三种体系架构
C/S 模式
P2P 模式:拓展性强,管理困难
混合模式:一部分任务在C/S模式,一部分在P2P模式
例如文件传输应用,文件的检索可以是C/S模式,文件到的下载是P2P模式;即时通讯软件:在线状态的判断是C/S模式,两个用户聊天的时候是P2P模式
应用需要解决的问题
两个应用进程之间通讯,如果是同一台主机,就使用操作系统的通信方式,如果是不同的主机,就要用到网络了。
写应用要考虑三个问题
如何区分主机的应用进程
这个就是靠Socket了。Socket是一个整数,代表了 IP + 端口号了。
- 对于TCP,Socket是两个主机的 IP 和 端口号。两边的IP确定了主机就确定了,两边的端口号确定了,对应的应用进程也就确定了。这四个数字就可以唯一确定一条连接。
- 对于UDP,Socket是本地的 IP 和 端口号。
如何用传输层提供的服务
传输层向应用层提供的服务有两类
- TCP(面向连接)
- 可靠保序字节流
- 流量控制
- 拥塞控制
- UDP(无连接)
- 快速
对于任何一个连接,需要告诉别人三个东西
- 目标主机IP和应用进程的端口号(收件人)
- 自己的主机IP和应用进程端口号(寄件人)
- 要传输的报文(寄出去的东西)
有了这3个内容后,就可以选择一种传输层的服务往下传了
在实际传输过程中,对TCP,前两个被打包成了 socket ;对UDP,只把第二个打包成了socket,但是传输过程中要额外提供第一个。
如何实现编写程序
这个就靠协议了。
C/S模式
HTTP
为了实现Web应用,就有了HTTP协议。
Web是由对象构成的。一个对象就是一个文件(像是图像、文本这些的)。Web一般会有Html文件。Html文件包含文本,还包含其他对象(比如说图片)。这些对象在Html中是以url地址的形式储存的。浏览器绘制网页时,就一个个找出html文件中的对象,然后把他们画出来。
url 格式:
Prot://user:psw@www.someSchool.edu/someDept/pic.gif:port
特点
HTTP协议采用 C/S 模式,通过 TCP 协议进行传输,端口号为80,无状态
无状态:HTTP不保存任何用户相关的信息
HTTP协议有两种非持续性连接(HTTP 1.0)和持续性连接(HTTP 1.1)
非持续性连接:客户端收到服务器的响应后关掉TCP连接
持续性连接:客户端收到服务器的响应后依然保持连接,超过一定时间后关闭
这里还可以细分
- 流水线模式:请求收到回复前接着请求
- 非流水线模式:一个请求得到回复后再发另外一个请求
报文格式
HTTP有两种报文格式:请求报文和响应报文
请求报文
有GET,POST,HEAD,PUT,DELETE等命令
| 名称 | 内容举例 |
|---|---|
| 请求行 | GET /somedir/page.html HTTP/1.1 |
| 首部行 | Host: www.someschool.edu\nUser-agent: Mozilla/4.0\nConnection: close\n Accept-language:fr |
| 空行 | |
| 实体主体 | (数据) |
客户端向服务器提交信息不是必须使用POST请求,还可以使用 GET + 参数 的形式
响应报文
有一些状态码
| 响应状态码 | 解释 |
|---|---|
| 200 OK | 请求成功,请求对象包含在响应报文的后续部分 |
| 301 Moved Permanently | 请求的对象已经被永久转移了;新的URL在响应报文的Location: 首部行中指定;客户端软件自动用新的URL去获取对象 |
| 400 Bad Request | 一个通用的差错代码,表示该请求不能被服务器解读 |
| 404 Not Found | 请求的文档在该服务上没有找到 |
| 505 HTTP Version Not Supported | - |
报文的形式大概是这样的
| 名称 | 内容举例 |
|---|---|
| 状态行 | HTTP/1.1 200 OK\r\n |
| 首部行 | Connection close\r\n Date: Thu, 06 Aug 1998 12:00:15 GMT\r\n Server: Apache/1.3.0 (Unix) \r\n |
| 空行 | |
| 数据 | (数据) |
Cookie
由于Http是无状态的,但是网页有识别应用的需求。因此就有了Cookie来让Http识别。
Cookie的实现是这样的

Cookie的四个组成部分
- 在HTTP响应报文中有 一个cookie的首部行
- 在HTTP请求报文含有 一个cookie的首部行
- 在用户端系统中保留有 一个cookie文件,由用户的浏览器管理
- 在Web站点有一个后端数据库
Web缓存(代理服务器)
Web由于采用C/S模式,源服务器压力会很大,为了改善上网体验就有了Web缓存,可以不直接访问源服务器就可以获取请求内容。
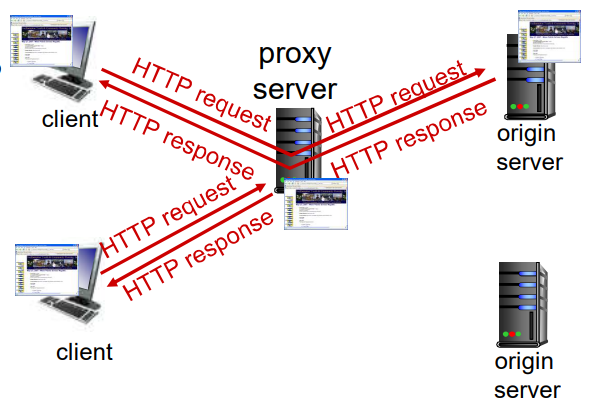
用户设置浏览器通过缓存访问Web后,浏览器将所有的HTTP 请求发给缓存,然后根据
- 对象在缓存中:缓存 直接返回对象
- 对象不在缓存:请求原始服务器,然后再将对象返回给客户端
有了缓存,有以下的好处:
- 降低客户端的请求响应时间
- 可以大大减少一个机构内部网络与Internent接入链路上的流量
- 互联网大量采用了缓存,可以使较弱的ICP也能够 有效提供内容
为了实现缓存的功能,Http添加了条件Get语句
- 缓存器: 在HTTP请求中指 定缓存拷贝的日期
If-modified-since:<date> - 服务器:
- 如果缓存拷贝陈旧,则正常响应报文,比如:
HTTP/1.0 200 OK - 如果缓存拷贝最新,则响应
HTTP/1.0 304 Not Modified
- 如果缓存拷贝陈旧,则正常响应报文,比如:
FTP
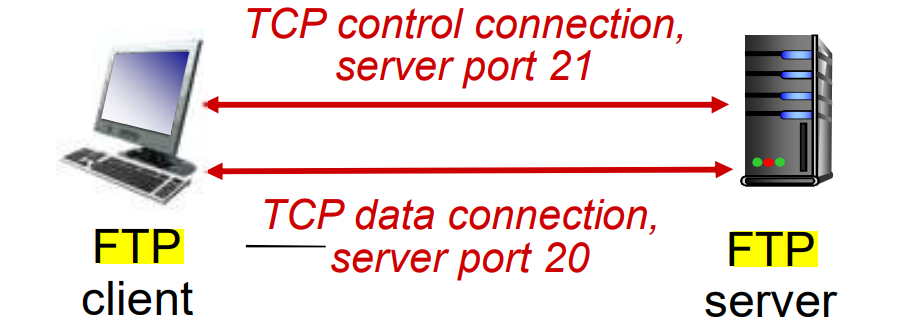
文件传输协议
HTTP协议采用 C/S 模式,通过 TCP 协议进行传输,端口号为21,有状态,将数据与控制分开
FTP协议需要两条TCP连接
- 控制连接:获得身份认证,以及实现浏览远程目录
- 数据连接:收到传输命令后开始连接,这个连接就专门用来传输文件
这种控制与数据分开的连接就叫做 带外传送
FTP的响应报文和Http一样
邮件
邮件系统由 用户代理、邮箱服务器和SMTP 组成。
用户写完邮件之后把文件通过用户代理发送给邮件服务器。
- 用户代理:管理邮件,撰写、编辑和阅读邮件都在这个上面
- 邮箱服务器:收、发、管理邮件
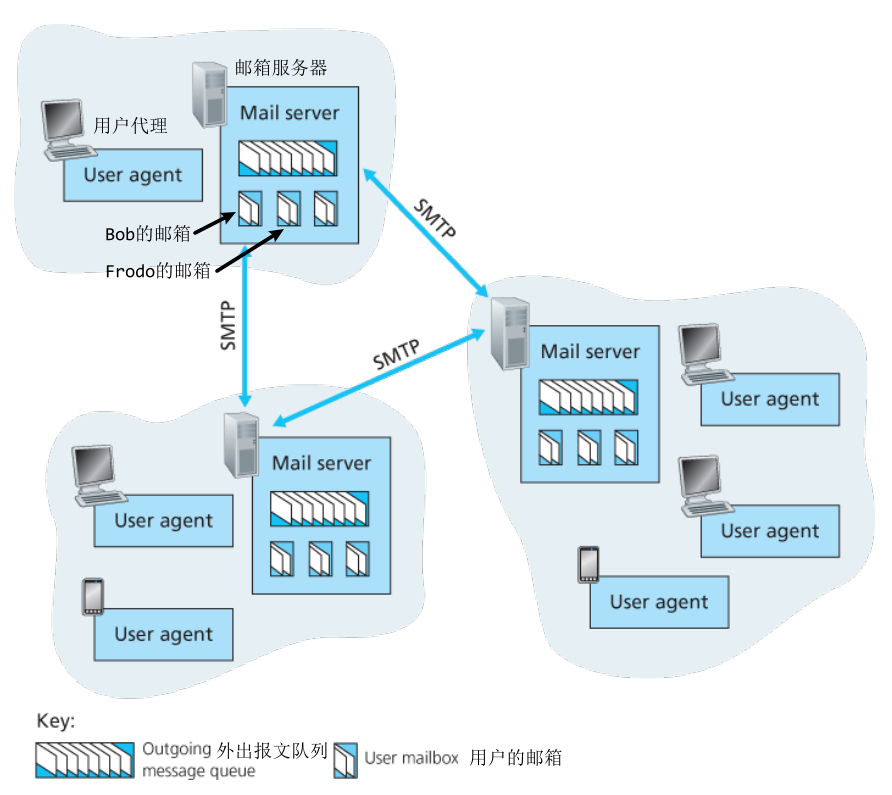
发送邮件的过程:
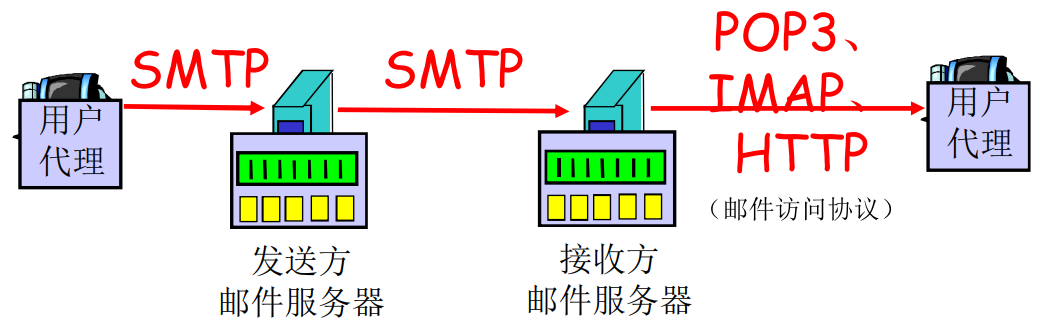
- 用户写好邮件后,用户代理将用户的邮件发送到发件人的邮件服务器,
- 发件人邮件服务器将邮件放入外出报文队列中。
- 当队列积攒到一定程度后,发送方邮件服务器与接收方邮件服务器建立TCP连接,使用SMTP协议传输文件。
- 接收方将收到的邮件放入对应用户的邮箱中
- 接收方通过用户代理访问接收方邮件服务器的该用户的邮件内容
SMTP
HTTP协议采用 C/S 模式,通过 TCP 协议进行传输,端口号为25
SMTP与HTTP的区别
HTTP是一个拉协议,用户通过请求拉取服务器的内容。
SMTP是一个推协议,用户把文件推向服务器
HTTP把文件中的图片这些对象封装在其他的响应报文中
SMTP把所有对象都放在一个报文中
HTTP报文可以是非7位ASCII码
SMTP报文必须是7位ASCII码,图片这些通过MIME转成ASCII
MIME: 多媒体邮件拓展
邮件访问协议
邮件的访问是通过邮件访问协议实现的
- POP3:有用户身份确认 (代理<—>服务器) 、事务处理(用户代理获取邮件、删除邮件)、更新三个阶段。无状态
- IMAP:在POP3的基础上增加的很多新的内容,比如说文件夹的管理。有状态。
- Http
P2P模式
P2P有以下3类
- 集中式目录
- 完全分布式
- 混合体
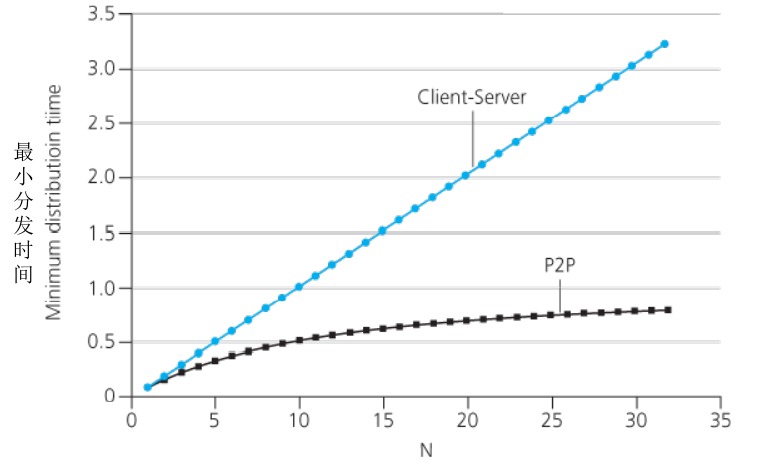
P2P 模式相比 C/S 模式的有点是可拓展性强。并且随着节点数量的增加,C/S 模式的文件分发时间随线性增加,P2P 模式增加的很慢
假设服务器要分发N个大小为F的同一个文件给用户,服务器的上传带宽为 $u_s$,客户端的下载带宽为 $d$。
- C/S 模式,服务器需要一个一个的发出去,分发的时间为 $t_{\text{C/S}}=\max\{\frac{NF}{u_S},\frac{F}{d_\min}\}$
- P2P 模式,服务器只需要发送一个文件,其余的各个P2P的对等体互相传输,分发的时间为 $t_{\text{P2P}}=\max\{\frac{F}{u_S},\frac{F}{d_{\min}},\frac{NF}{u_s+\sum u}\}$
典型 P2P 应用:Napster,Gnutella,KaZaA,BT,DHT
DNS
应用层层面的网络基础设施
DNS是运行在53号端口上的应用服务,是网络运行在应用层上的核心功能,主要使用UDP实现
DNS的作用主要是把域名变为IP地址,不过还有其他作用
- 主机别名与规范名之间的转换
- 邮件服务器别名与规范名之间的转换
- 负载分配
DNS的主要思路是
- 分层次、基于域的名字划分
- 分布式的数据库完成域名到IP的转换
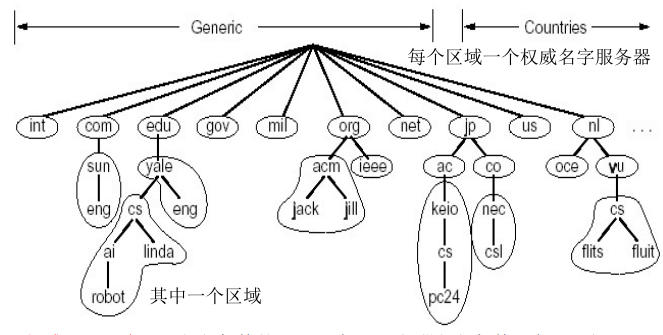
IP地址的划分
DNS采用层次树结构的命名方法,域名的根在全球13个根名字服务器上。这些根被划分成了很多顶级域。从顶级域往下,划分为若干子域名。树的叶子就是一个主机。
顶级域大致有两类:通用的(
.com)和国家的(.cn)
域名到IP的转换
由于使用单服务器会产生单点故障、拓展性差和距离远近等问题,DNS采用分布式的数据库。
每个域被划分成一块一块的区域,一个区域内的主机有一个权威名字服务器,权威名字服务器中记录这个区域中每个主机的IP和域名的对应关系,找到权威名字服务器就找到了这个区域所有主机域名和IP的对应关系。同时,每个ISP都有一个本地服务器
DNS服务器以资源记录(RR格式)的方式记录域名和IP的对应关系
| 类型名称 | 解释 |
|---|---|
| Domain_name | 域名 |
| Ttl | 生存时间(权威,缓冲记录) |
| Class | 对于Internet,值为IN |
| Value | 可以是数字,域名或ASCII串 |
| Type | 见下表 |
| 类型 | Name | Value |
|---|---|---|
| A | 主机 | IP地址 |
| CNAME | 规范名别名 | 规范名 |
| NS | 域名 | 该域名的权威服务器域名 |
| MX | 邮件服务器别名 | 邮件服务器规范名 |
域名解析有以下步骤
- 域在DNS缓存中或在就在该区域中:直接访问这个区域的本地DNS服务器就可以得到IP地址
- 域不在缓存中或该区域中:联系根名字服务器顺着根 -> TLD 一直找到权威名字服务器
通过缓存可用提高效率,缓存中每个记录有TTL来实现数据更新
这种查询分为迭代查询和递归查询两种
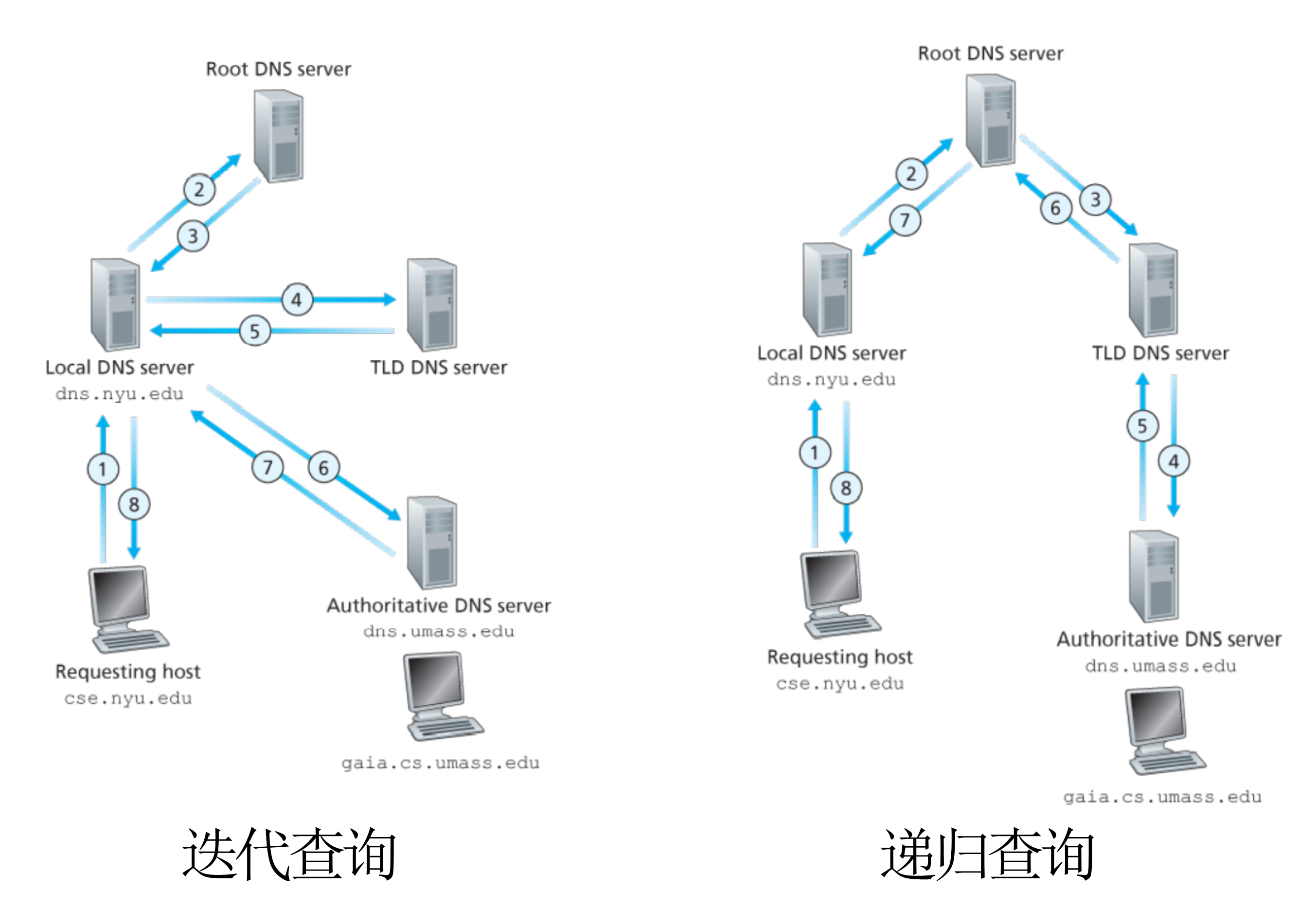
递归查询问题是根服务器负担过大
DNS的维护
DNS的请求和响应报文格式相同:
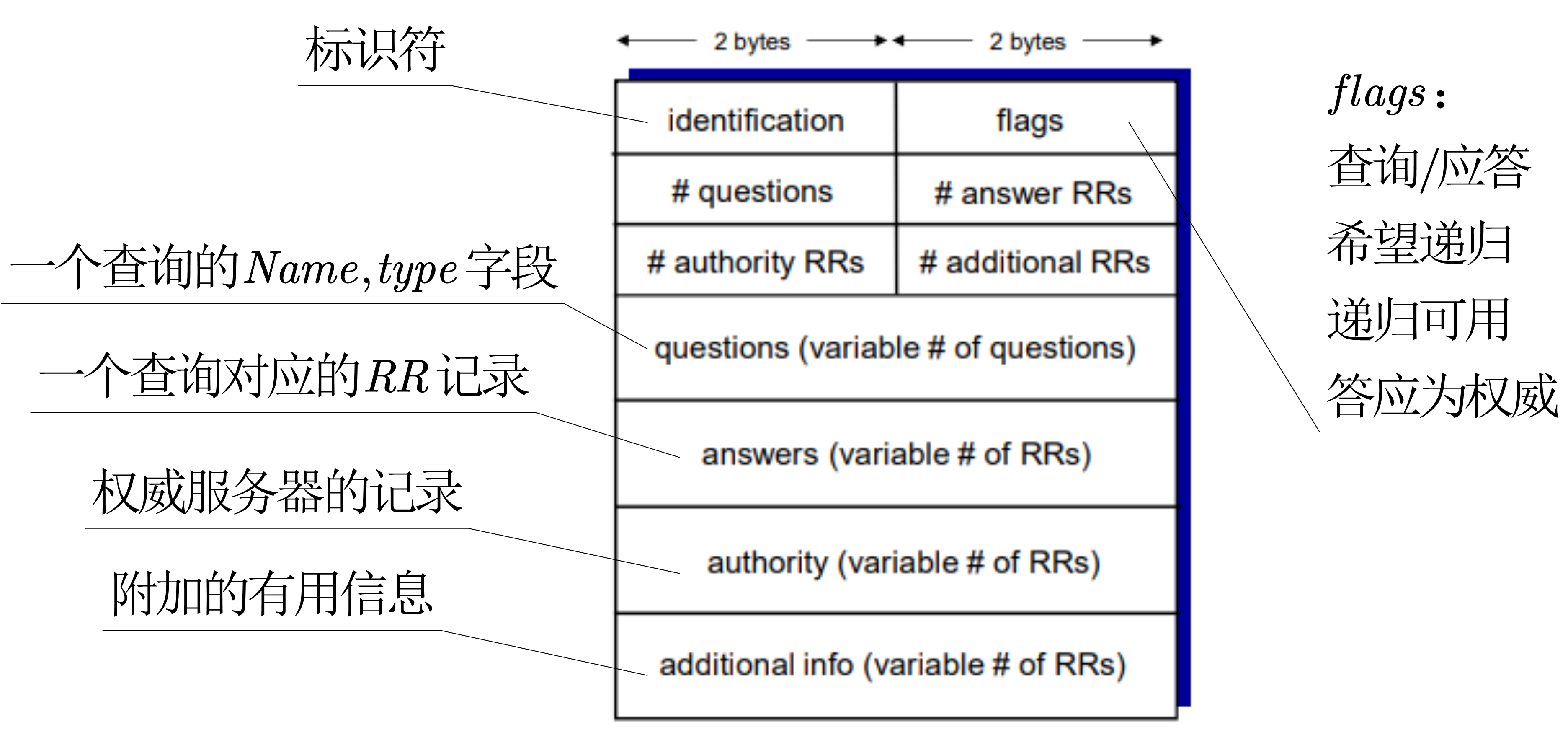
互联网视频服务
随着因特网视频的火热,需要为成千上万的人提供并行的视频播放服务,这时候需要解决两个问题
- 同时向超大规模的用户提供并行的服务(告示文件+域名解析重定向+CDN内容靠近客户)
- 不同的用户,处理数据的能力不同(DASH协议)
CDN就是来解决着两个问题的
DASH协议
Dynamic Adaptive Streaming over HTTP,经HTTP的动态适应流。用来解决第二个问题的
- 对服务器的每个视频,把视频写成一块一块的,然后处理成各个不同清晰度的版本。通过告示文件提供各个版本的URL。
- 客户端根据网络情况动态的请求不同清晰度的版本。
CDN
由于单服务器有 单点故障、服务器到客户端跳数多、网络重复流量多,因此采用CDN的服务。
CDN在全球部署服务器,视频提供商购买CDN的服务,预先将视频缓存到CDN的服务器上。用户通过域名的重定向,访问离用户最近的缓存节点,从而实现加速。
CDN部署服务器有两种策略
- 深入,CDN在local ISP的附近部署缓存节点。跳数少,用户享受服务好,但是服务器多,维护成本高
- 邀请做客,在少数一些关键的地方设置缓存节点

套接字编程
TCP
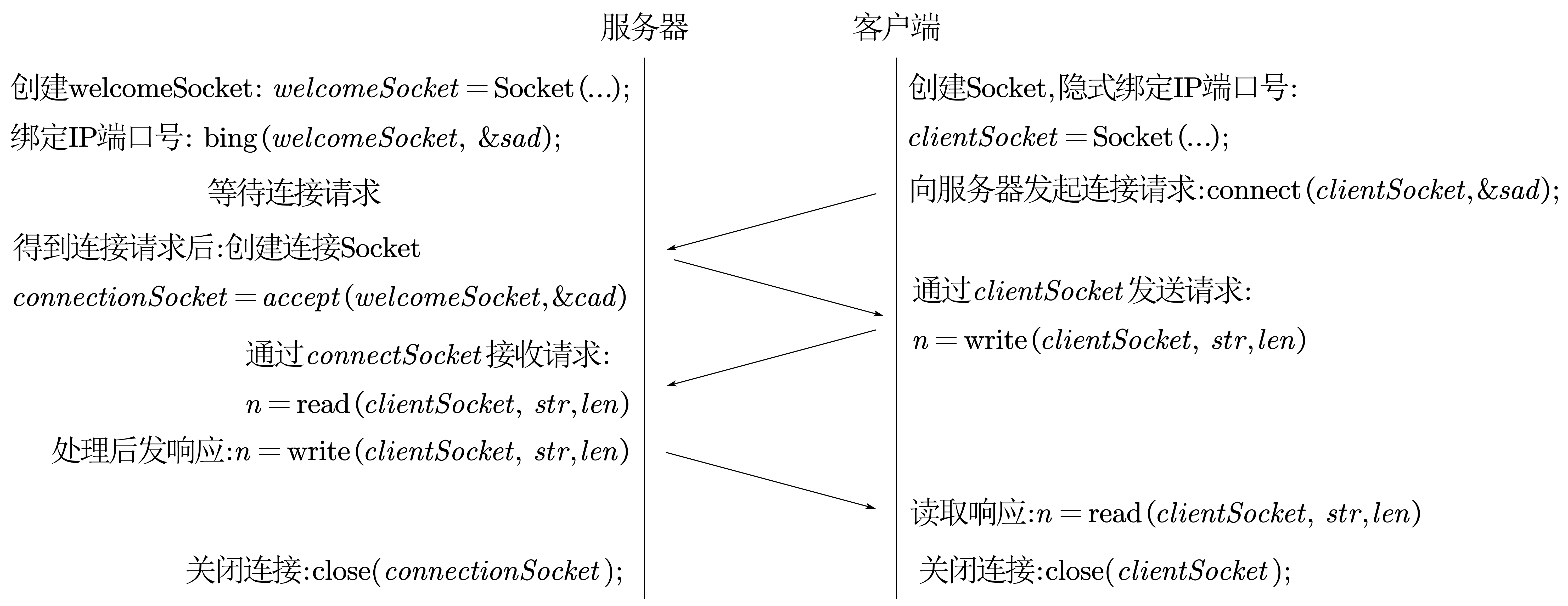
UDP
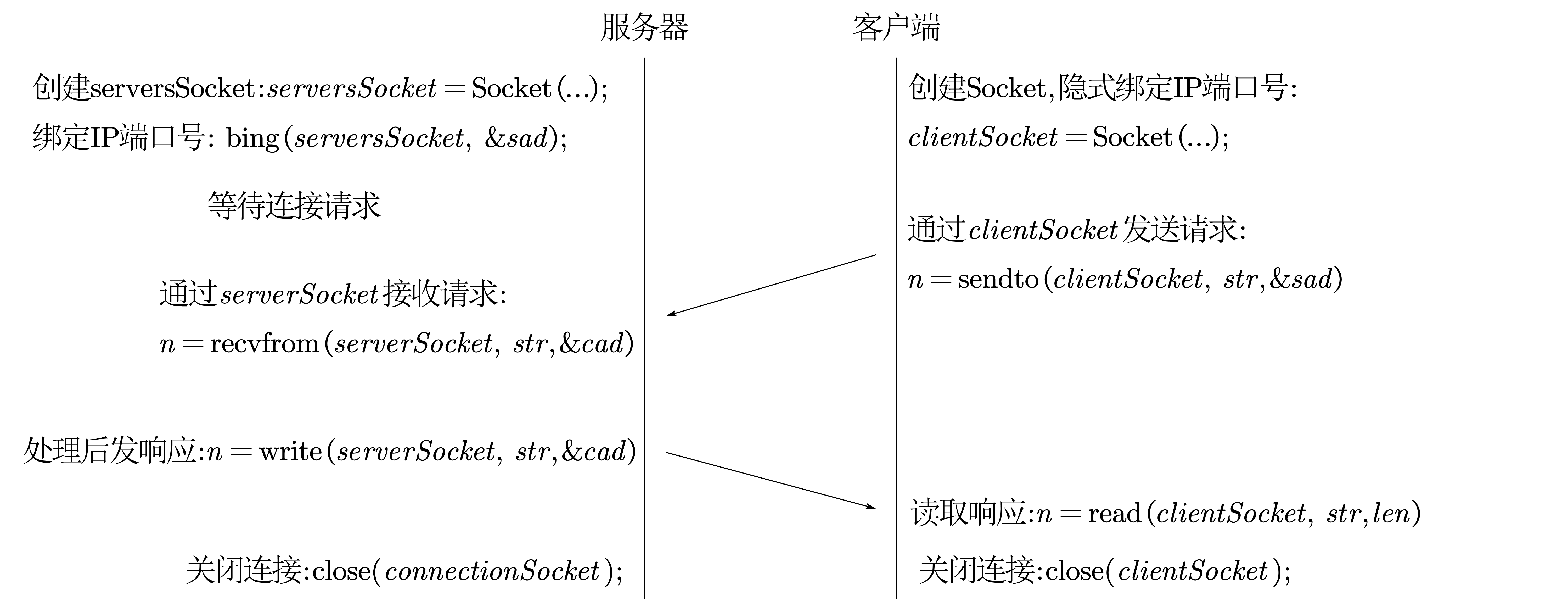
cad 和 sad 是两个结构体,里面放着 IP 和端口号,cad是客户端的,sad是服务器的
传输层
传输层就只有两个协议了,TCP和UPD,这一章的重点是TCP保证数据传输可靠的原理
传输层的服务是保证应用进程之间的逻辑通信,而网络层的服务是保证主机之间的逻辑通信,而这样的逻辑通信往往是不可靠的。传输层就是要通过自己把不可靠的服务变为可靠的服务。
提供了进程的区分,加强了网络层的服务
有一个很好的例子
1 | |
传输层多路复用/解复用
多路复用 就是发送方应用层给传输层很多不同的Socket,传输层把Socket对应的IP和端口号封装在头部生成报文段,从而可以统一通过网络层发送的过程。
多个应用都采用 TCP 或 UDP 传输数据
多路分解(解复用) 就是接收方传输层从报文中提取IP和端口号,把报文信息交给对应的应用进程
数据解封装,区分应用进程
TCP多路复用解复用
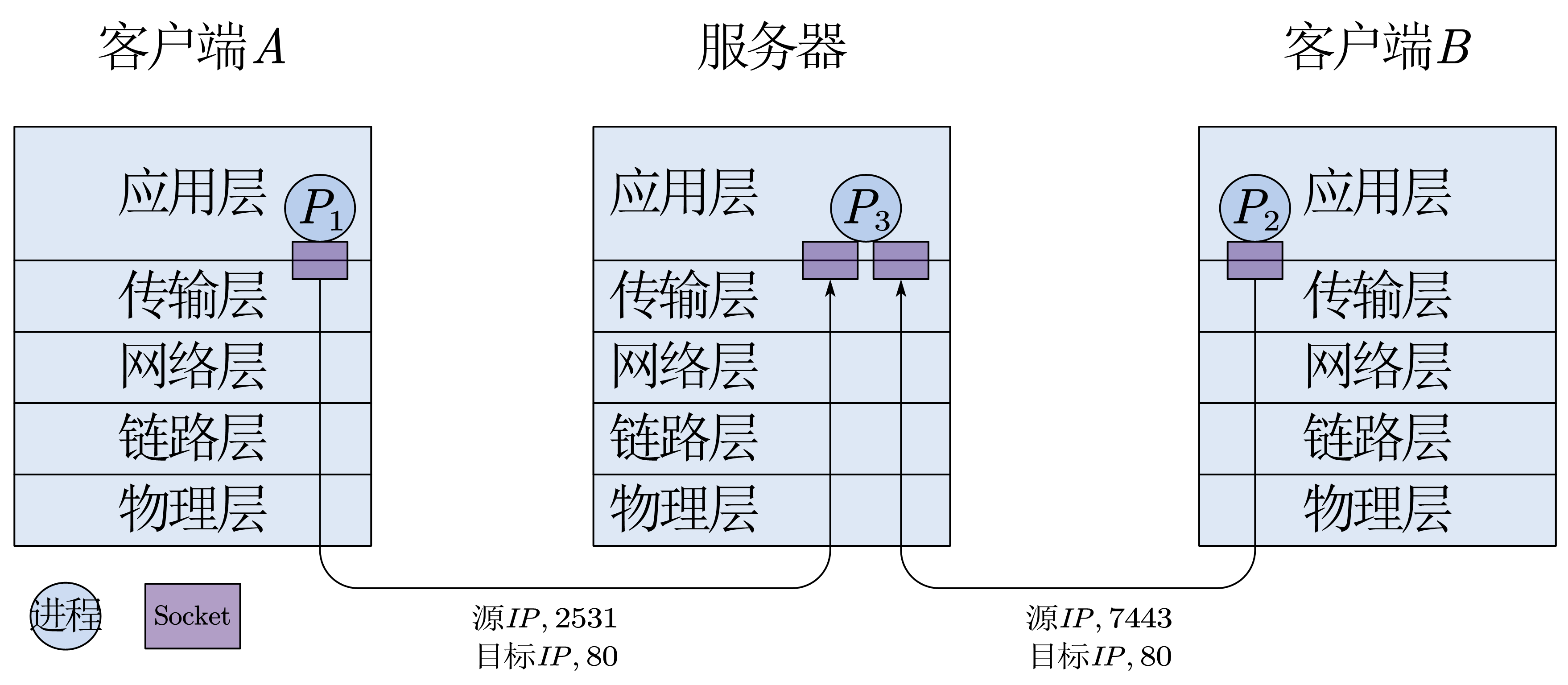
TCP 的 Socket 是一个包含源IP,源端口,目标IP,目标端口的一个四元组,因此只要其中一个不同,就是不同的Socket,分发给不同的应用进程
UDP多路复用解复用
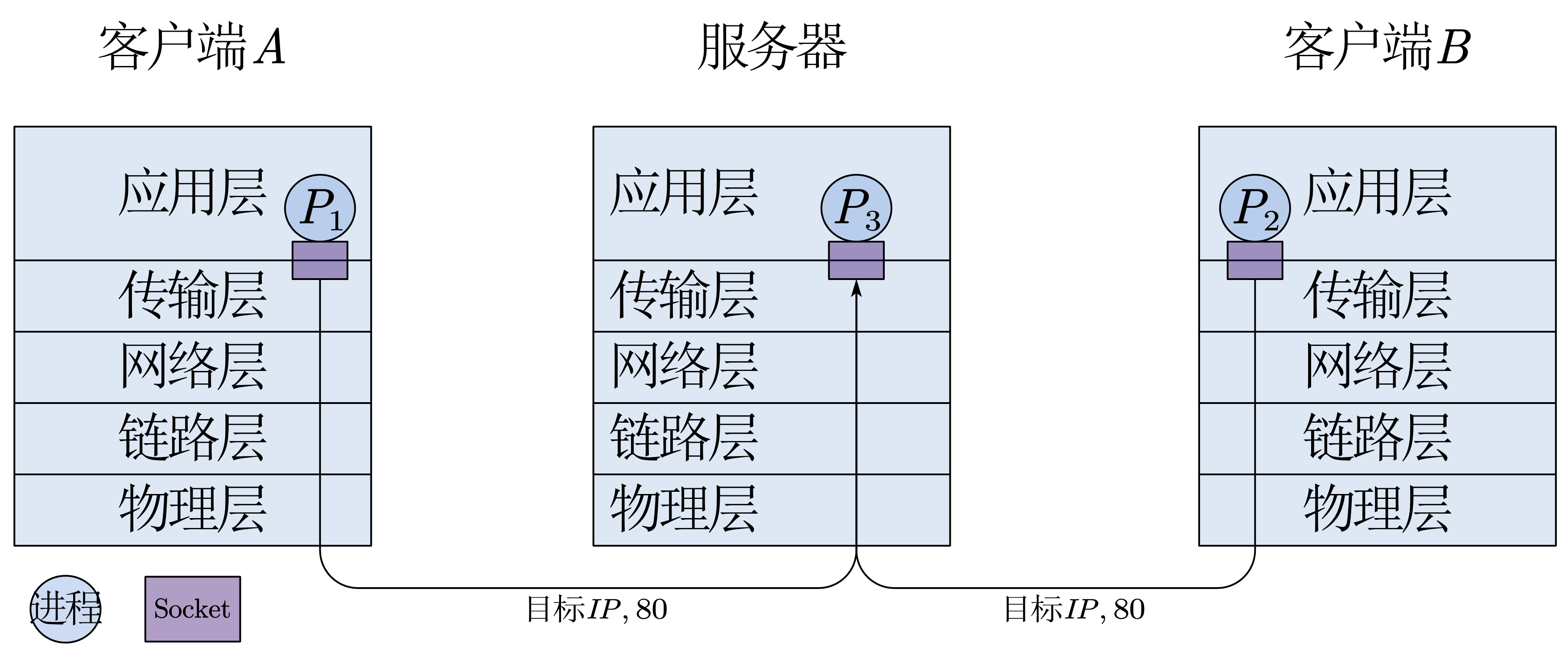
UDP 的 Socket 是 本地 IP,本地端口的二元组
UDP
User Datagram Protrol。UDP就是在 IP 的基础上加了多路复用解复用的功能和校验和的功能,其他基本上和 IP 的一样。
优点
- 不会建立连接(建立连接有额外的延时)
- 简单
- 报文头部开销少
- 无拥塞控制和流量控制,可以尽可能快的发送数据
报文
就8个字节,4个字段。每个字段两个字节,分别是:目标IP,目标端口,长度和校验和
校验和
校验和的目的就是将报文段的内容看成 16bit 的数字,然后这些数字和校验和相加后,每一位都要是1
校验和的计算:将报文段看成 16bit 的整数加起来,最高位进位了则回卷(在结果的最低位加1)。得到的数字取反就是校验和
可靠数据传输原理
传输模型如下
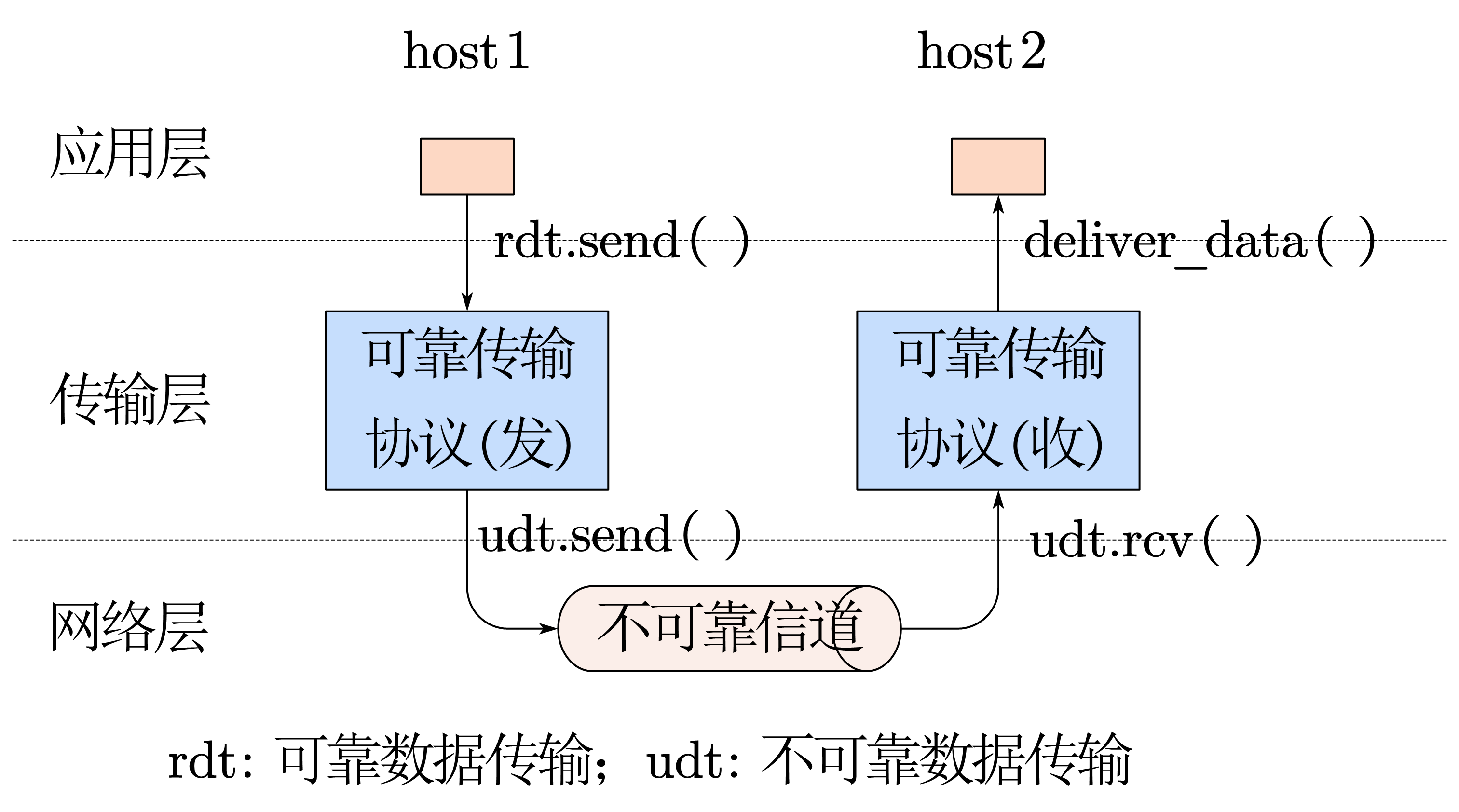
rdt1.0
假设:网络层提供的服务是可靠的(不出错,不丢失)
实现:此时只需要封装解封装就可以了,只起到一个区分应用进程的作用
rdt2.0
假设:传输的数据可能出错
实现:增加 差错检测、接收方反馈 和 重传
问题:没有考虑反馈出错的可能性
rdt2.1
实现:增加序号
rdt2.2 :把NAK变为了ACK+序号的机制
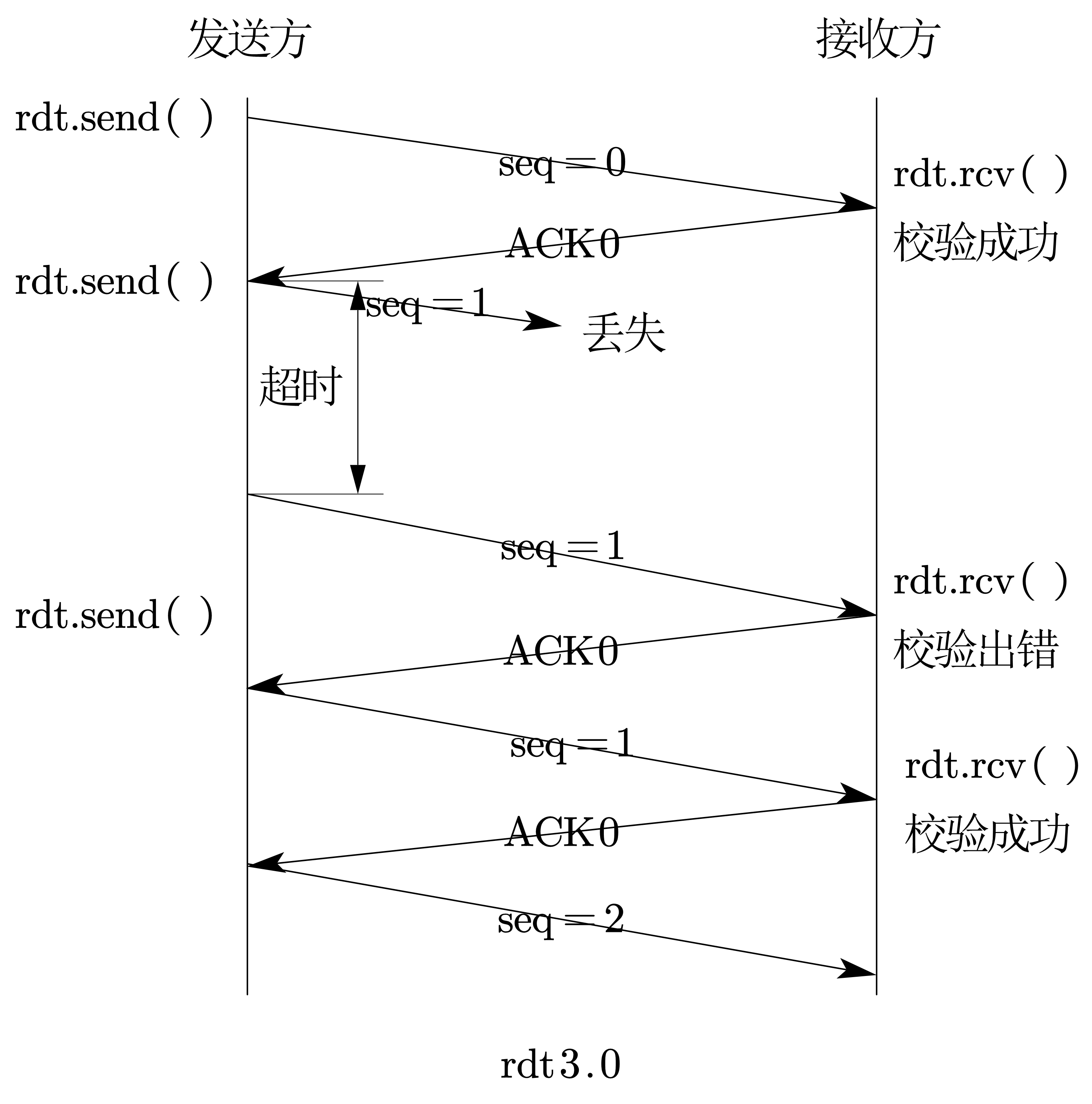
rdt3.0
假设:传输的数据既可能出错,又可能丢失
实现:增加超时重传机制
流水线
rdt3.0的是停止转发协议。发一下停一下,效率比较低。然后通过设置缓冲窗口,可以用流水线的方式来提高效率.
就是在未经确认的情况下,连续发送多个分组。
| 名称 | 发送窗口 | 接收窗口 |
|---|---|---|
| 停止转发 | = 1 | = 1 |
| GBN | > 1 | = 1 |
| SR | > 1 | > 1 |
发送窗口的大小就是未经确认分组的数量
GBN协议
回退N步协议(Go Back N)
对于发送方,一次性的把发送窗口中的所有的数据全部发送出去,并且缓存不抛弃,然后等待接收方的反馈。
- 收到接收方的接收成功的数据:把成功的那个数据包和它之前的标记为已发送,然后抛弃掉,后面的数据包进入发送窗口,向接收方发送
- 接收超时:把发送窗口中的所有发送未确认的数据包全部依次发送给接收方
累计确认
对于接收方:只能顺序的接收分组
- 接收到正常分组:向发送方发送ACK对应序号
- 收到重复分组,或者不是接收方正在等待的分组:抛弃,并发送之前的确认信号
序号是0,1,2,3,4:如果2出错了,即使3,4正常收到了也丢弃掉
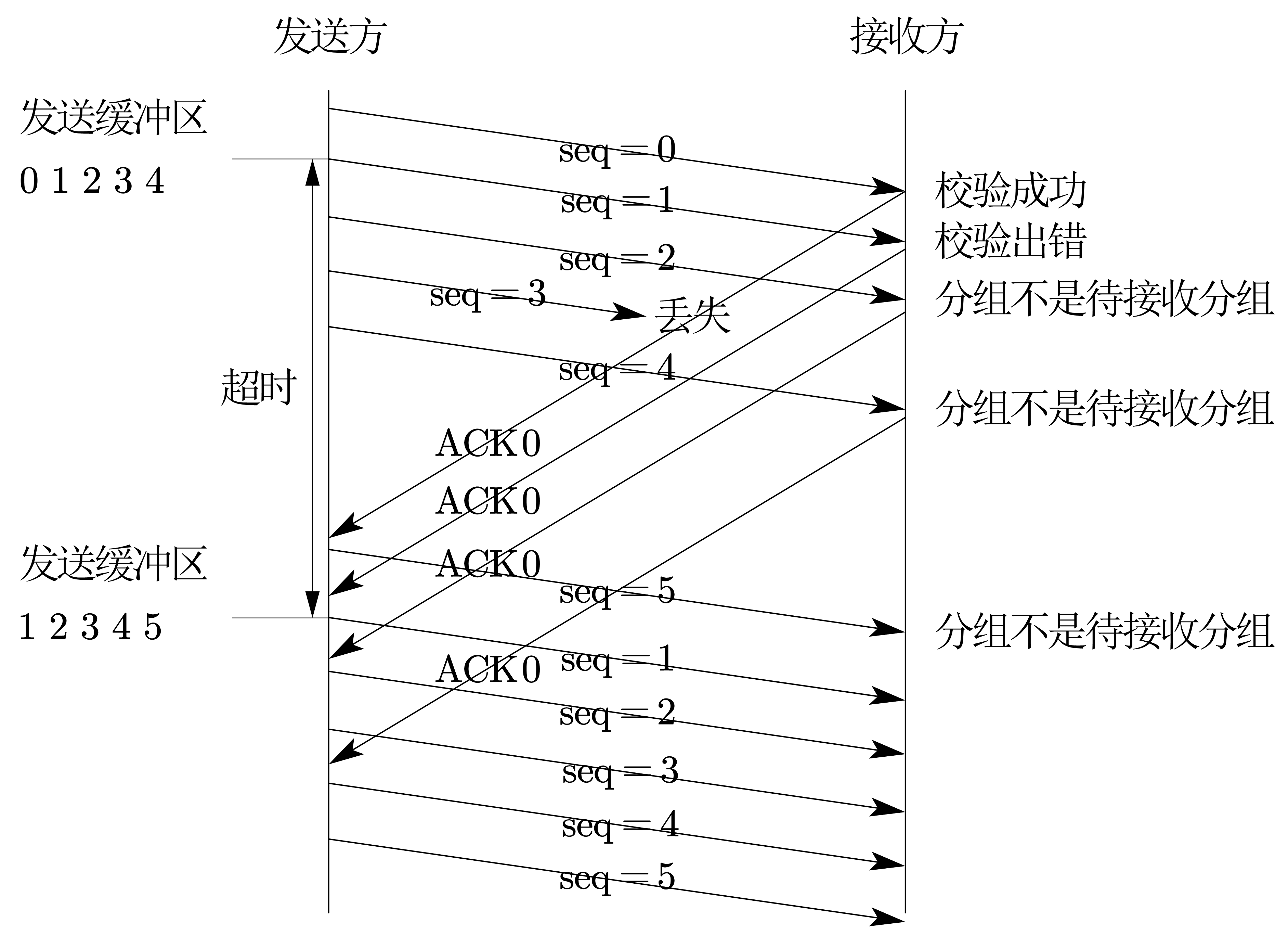
其中的2,4号数据传过去了但是抛弃掉了,就很浪费
SR协议
选择重传协议(Selective Repeat)
由于接收窗口也可以缓存了,那么就可以乱序的接受分组了。另外,接收方的确认也不再是累计确认,而是收到一个发送对应的确认。
对于接收方,分组只对没有收到确认回复的分组重新发送

| 项目 | GBN | SR |
|---|---|---|
| 优点 | 简单,占用资源少 | 出错时重传代价大 |
| 缺点 | 一旦出错,回退N步,代价大 | 复杂,占用资源多 |
| 用途 | 出错率很低的情况 | 链路容量大的情况 |
总结
| 名称 | 用途 |
|---|---|
| 校验和 | 确认分组是否正确 |
| 肯定确认 | 确认分组是否收到 |
| 序号 | 检查重复 |
| 定时器 | 处理丢失 |
| 流水线 | 解决停止转发效率低的问题 |
拥塞控制原理
拥塞原因与代价
原因是主机向网络核心发送的数据过多,超过了网络核心所能承载的能力
代价:
- 当分组的到达速率接近链路容量时,路由器的排队延时会趋向于无限大
- 网络延时很大,造成丢包严重。
- 发送包在遇到大的时延,会发送重复的副本,降低链路的利用率
- 分组丢失使得上游路由器的传输容量浪费了
拥塞控制手段
端到端的拥塞控制
TCP就是使用的这种,端系统根据自己的探知,判断网络的拥塞情况。
网络辅助的流量控制
网络核心向发送网络拥塞的状态信息给端系统
TCP
特性
- 可靠保序字节流,流水线,流量控制,拥塞控制;面向连接,全双工
单工:$A\rightarrow B$
双工:$A\leftrightarrow B$
全双工:$A\rightleftharpoons B$
段结构
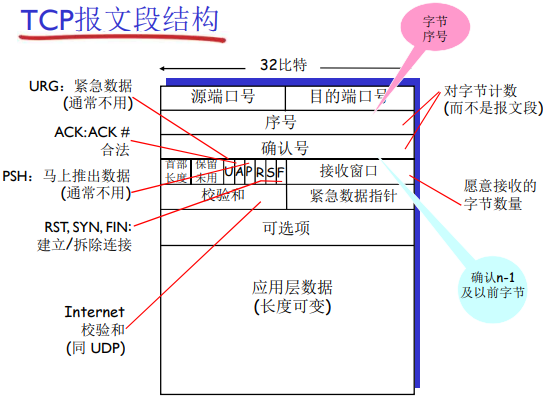
TCP的序号:TCP的序号发送端和接收端是不同的,一般来说这个序号是一个随机的序号。这个序号表示PDU首字符在字节流中的位置。确认是对下一个字节的期待(顺序收到的字节的最后一个+ 1)。

TCP连接在连接握手阶段两台主机会事先交换各自的序列号
发送端和接收端是不同的原因:这两个不同目的是为了防止老的TCP连接的数据对新TCP连接的数据造成干扰
超时时间的设置
$\alpha,\beta$ 是任取的,推荐 $\alpha=0.125.\beta=0.25$
公式不重要。主要是超时时间的设置是一个平均数+4倍的方差的形式。然后这个平均数是指数移动平均,随着时间的增加,前面的数据会越来越不重要。
可靠数据传输
TCP用的是GBN和SR的混合,它和GBN一样是采用的累计确认的方式。
它还增加了 快速重传(在超时定时器中断之前,如果连续3个冗余的ACK的,它会立即重传)
同时当它还会 延迟确认,当对另一个按序报文段的到达最多等待500ms。如果下一个报文段在这个时间间隔内到达,立即发第二个的ACK。没有到达,则发送一个自己的ACK。
还有超时事件发生时,超时间隔会加倍。
流量控制
目的:防止淹没接收方
手段:将接收窗口以捎带的方式发送给发送端,发送端发送的数据始终小于接收方的缓存空间。
连接管理
连接管理就两个部分,连接的建立和拆除
3次握手
因为发送端和接收端的序号是不同的,3次次握手主要是为了交换这个序号,并且做确认。
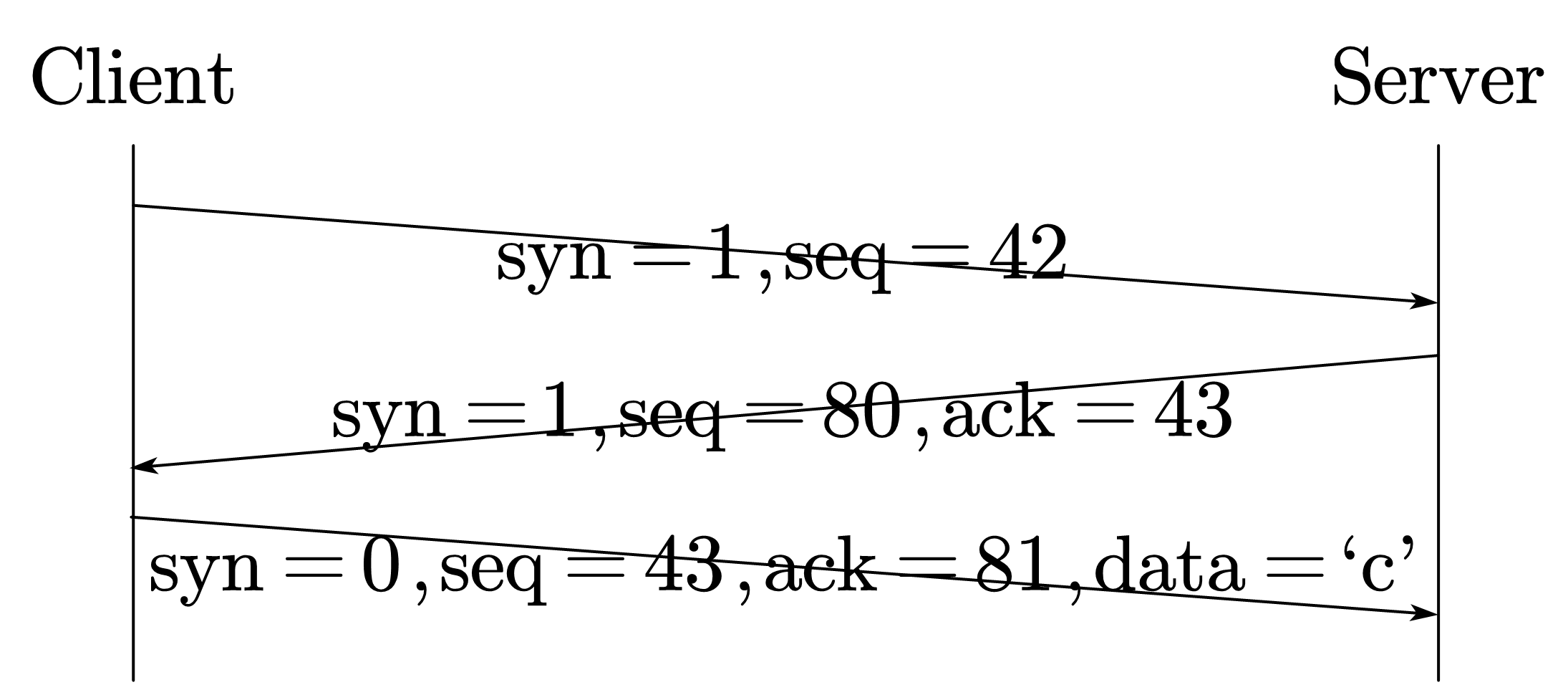
如果这两边的序号相同,就只需要两次握手了,但是两次握手会产生两个问题,第一个是半连接(只在服务器维护了连接),还有一个是老数据当新数据接收了
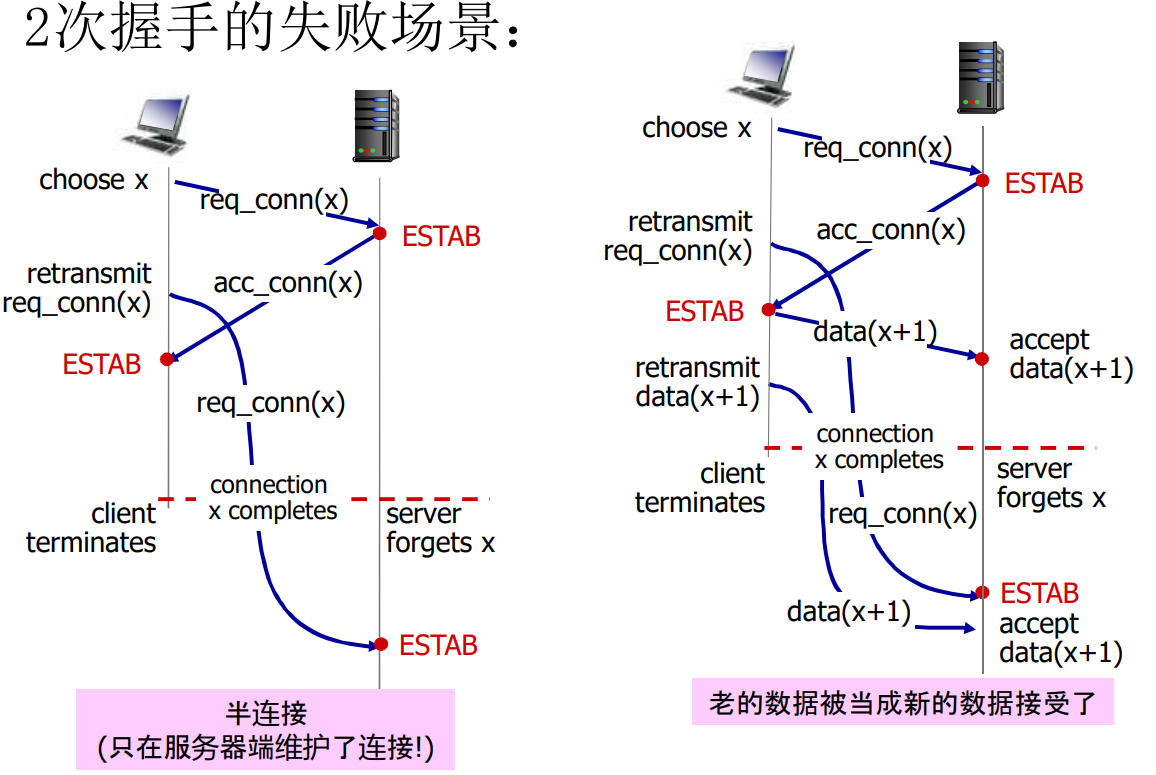
4次挥手
采用对称式的设计,有两军问题,靠定时器凑活解决
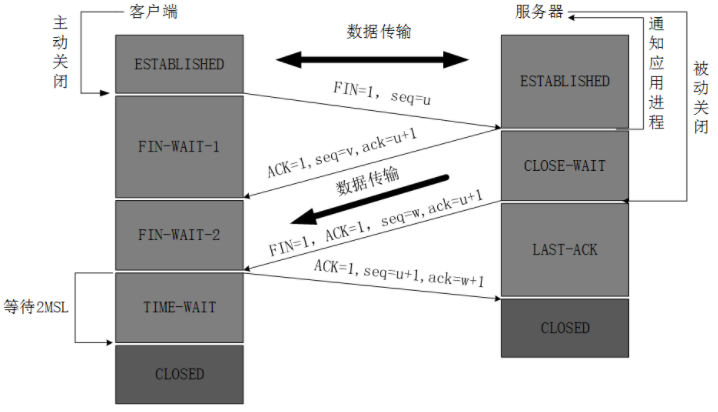
这里等 2MSL 是为了防止服务器的FIN丢失,重传的那一段,保证客户端发送的最后一个ACK报文能够到达服务器。同时,可以防止老的数据
拥塞控制
探知
- 超时定时器超时
- 收到3个冗余的分组
行为
发送端需要维护一个发送窗口,和一个发送窗口警戒值的两个值。
- 发送端超时定时器超时:发送窗口变为1,发送窗口警戒值变为原来的一半
- 收到3个冗余的分组:发送窗口变为原来的一半+3MSS,发送窗口警戒值变为发送窗口的一半 快速恢复阶段
- 正常情况:
- 发送窗口 < 发送窗口警戒值:每发送一个发送窗口就翻倍 慢启动阶段
- 发送窗口 > 发送窗口警戒值:每发送一个发送窗口 + 1 拥塞避免阶段
MSS 最大报文长度,一般是1460字节. 他需要保证加上一个TCP和一个IP的头部(20+20)后能在链路中传输(1500字节)

网络层
网络层提供的服务主要是主机到主机之间的通讯。
网络层有两大功能:路由、转发
- 路由:路由器相互配合,传递路由信息,然后根据路由选择算法来计算路由表。
- 转发:路由器收到一个分组后,把分组缓存下来,匹配分组的字段,根据路由表决定这个分组应该从那个端口发出去
网络层的协议包括 IP 协议、路由选择协议和 ICMP协议
原理
由于网络层本身十分的复杂,根据网络层两个重要功能,网络层可以被分为两个部分
- 数据平面:负责实现转发的功能,决定从输入路由器的数据报要输出到那个输出链路。
- 控制平面:负责实现路由的功能,控制数据报从源主机到目标主机的传输路径。
网络层的这两个平面有两种实现方式
- 传统方式
- 数据平面和控制平面竖直的集成在每一个设备中(路由器)
- 路由器分布式的计算路由表
- SDN通用转发方式(Software Define Network)
- 控制平面与数据平面分离,在不同的设备上实现
- SDN控制器上的网络层应用集中式的计算流表,SDN控制器向路由器下发流表
- 路由器根据分组的多个字段匹配流表,进行转发
数据平面
路由器原理
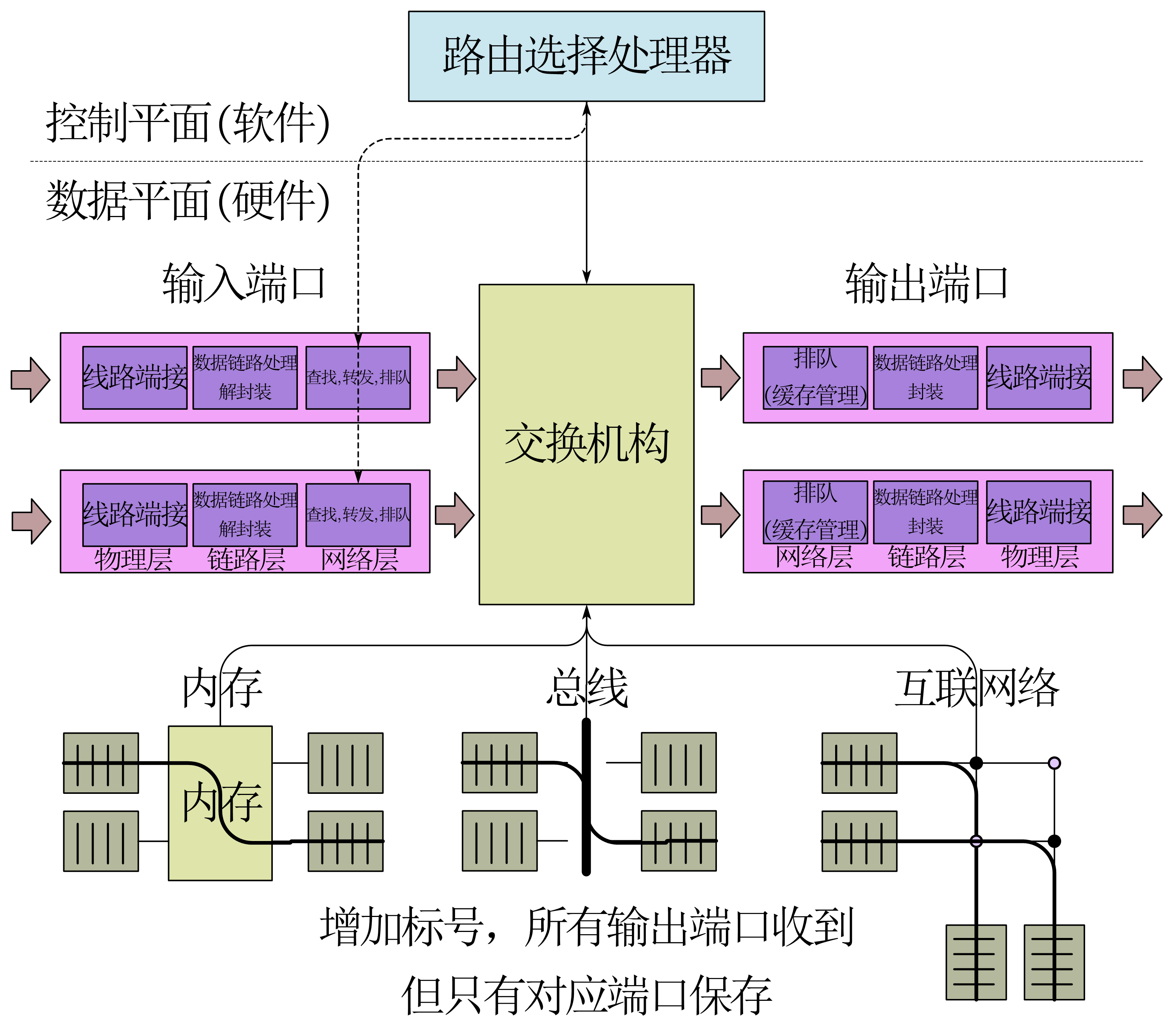
路由器由三个部分组成:输入端口、交换机构、输出端口、路由处理器
输入端口和输出端口都实现物理层、链路层和网络层的功能。其中输入端口负责查询路由表,输出端口涉及到分组调度
为了防止堵塞的情况,输入端口和输出端口的都有缓存,以实现排队
交换机构有三种实现方式:经内存交换、经总线交换、经互联网络交换
这个互联网络是电路上的一种称呼,与本文的互联网概念完全不同
路由处理器协调各个部分的工作
IPv4
IP协议为上层提供的服务是尽力而为的一种服务(可能会丢包、乱序、重复)
报文格式
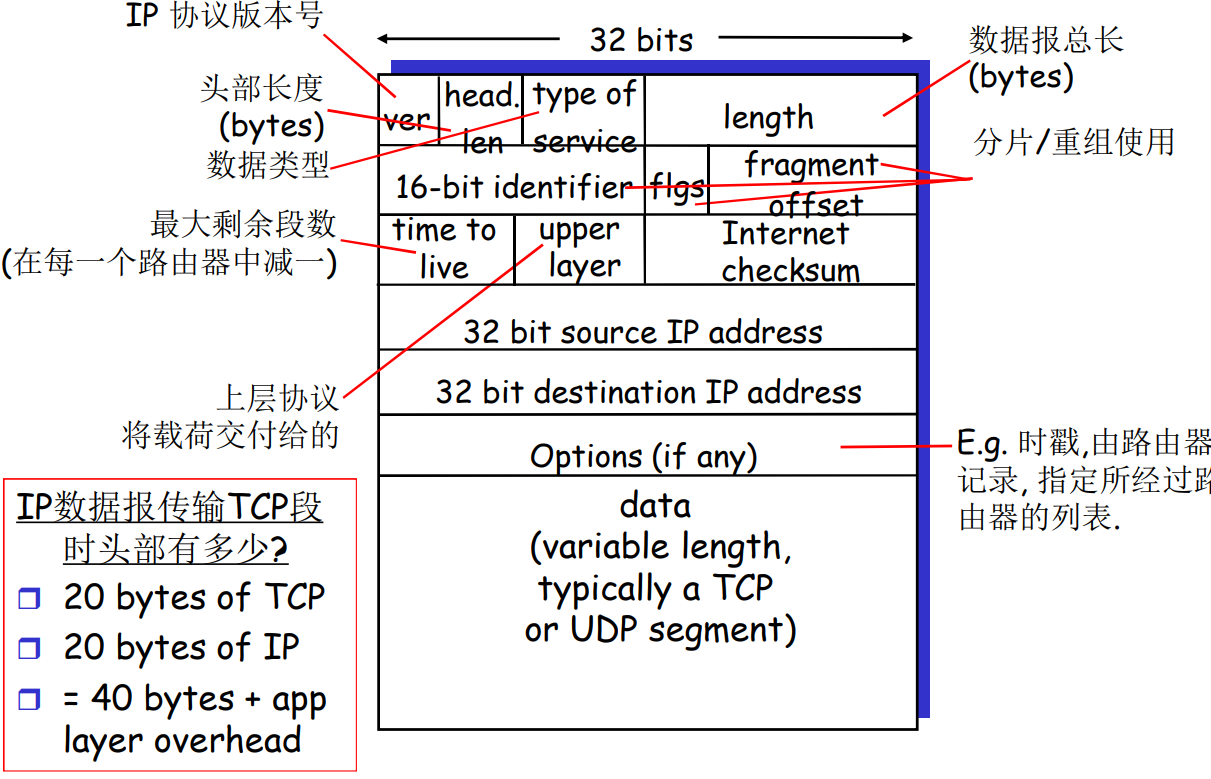
分片重组的原因:分组的大小超过了链路的MTU(最大传输单元)
分片的实现:IP协议的报文中有
identifier,flags,fragment offset三个值。identifier用于表示这些分片所属的分组,flag判断是否是最后一个分片,fragment offset表示这个分片数据的首字节在整个分组中的偏移量。
IPv4编址
IP地址:主机或路由器网络接口的标识,分为网络部分和主机部分
网络层为了提高效率,有 路由汇聚 的效应:连续子网前缀的子网可达信息可以做汇聚,以减少路由器路由表计算胡传输。(同一个子网的前缀相同,这样,他们就可以通过一个IP计算可达信息)
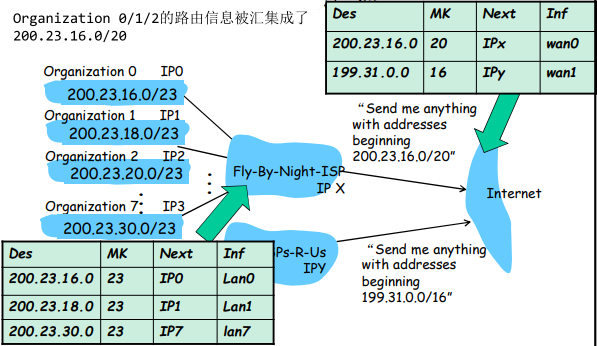
子网:
- 子网内的主机通信不需要借助路由器,链路层交换机即可
- 子网内主机的网络部分(子网前缀)相同
子网掩码
子网掩码和IP地址配合使用,子网掩码为 1 表是这个位在IP地址中是网络位。
IP地址分类
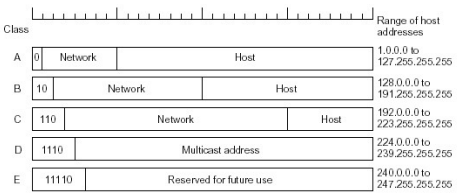
其中 D 类是多播,E类是预留的IP地址
DHCP
上网的主机通过DHCP获取 IP、子网掩码、默认网关和 Local Name Server
主机加入互联网后,向同一子网的所有主机广播 DHCP发现报文。同一子网的多个 DHCP 服务器收到报文后,广播DHCP提供报文,并在报文中附上自己的IP。主机收到 DHCP提供报文后
NAT
网络地址转换,工作方式如下
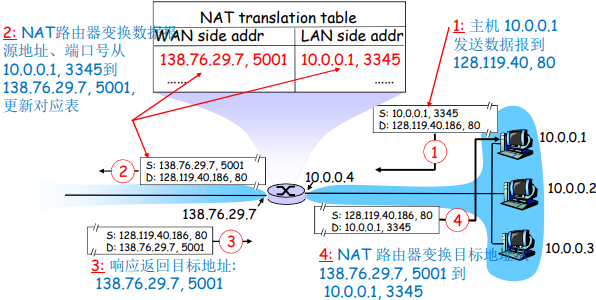
IPv6
从32位变为128位

IPv4到IPv6的迁移:隧道
SDN
工作原理
模式匹配 + 行动
SDN一次匹配报文的多个字段(传统模式下只匹配目标IP一个字段),行动除了传统的转发之外,还有泛洪、阻塞和修改字段等等
分组按照各级字段匹配流表,然后按照响应的行为动作执行
- 按照优先级进行判断,之后统计计数
优点
- 集中在控制器上实现逻辑,使得网络可编程,实现复杂网络的功能
- 形成开发生态(控制器,网络应用在一个框架下协作)
- 分组交换机按照流表转发,十分便宜,通用,便于升级
控制平面
控制平面的功能是路由:按照某种指标,找到源到目标的较好路径
网络层提供主机到主机的数据传输,或者说是 IP 到 IP 的数据传输,但是 IP 数量太大了,为每一个 IP 提供路由成本太高,现实是将IP汇集,实现从子网到子网的数据传输,这样大大减少了网络路由节点的数量。
路由选择算法
链路状态算法 (LS)
链路状态算法是一种全局的、集中式的算法。该算法在计算之前就拥有所有节点之间的联通性和链路开销信息。
具体过程:
- 发现相邻节点,获取对方IP
- 测量相邻节点代价
- 组装LS分组,描述相邻节点之间代价
- 以泛洪的方式扩散分组到其他路由器。路由器获得各节点LS分组,从而得到整个网络拓扑。
- 运用 Dijkstra 算法找出最短路径
Dijkstra 算法回顾:https://www.bilibili.com/video/BV1ts41157Sy
链路状态法会出现震荡的现象,当一条路径代价是0的时候,所有用LS算法的路由器都将将分组指向这条链路,从而使得这条链路代价增大。
距离向量算法 (DV)
距离矢量算法是一种局部的、分散式的算法。该算法维护自己和邻居节点之间的连通性和和链路开销信息。算法以迭代的方式最终到目标。
每个节点维护一个距离矢量(表),上面记录它到所有其他节点的下一跳和代价值。它和邻居节点定期交换 DV
DV算法使用 Bellman-Ford 公式不断迭代生成到所有目标的代价和响应的下一跳。
从 x 到 y 的代价 $d_x(y)$ = 从 x 到它邻居 v 的代价 $c(x,v)$ + 从 v 到 y 的代价
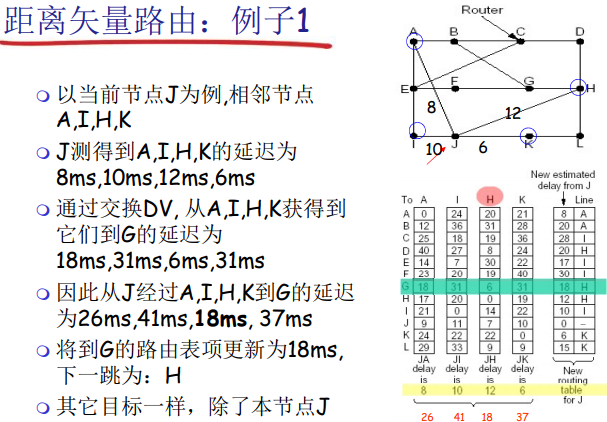
DV算法具有好消息传的快,坏消息传的慢的特点。
比较
- 报文复杂性:LS > DV
- 收敛速度:LS > DV
- 健壮性:LS > DV
路由选择协议
由于互联网过于复杂,实际的情况是采用层次化的结构。互联网被分为一个个 自治系统 (AS) ,他们之间有一个路由选择协议。各个自治系统中的路由器也有自己的路由选择协议。因此实际的路由选择协议被分为 内部网关协议 和 外部网关协议 。
层次化解决了规模性问题和管理性问题
规模性:路由设备数量大,路由选择信息的通信开销十分巨大
管理性:ISP希望按照自己的意愿运行路由器,同时希望对外界隐藏细节
内部网关协议
自治系统内一个主机到任意一个主机的路由选择协议,比较关注效率和性能
- OSPF开放最短路优先:基于LS算法
外部网关协议
自治区之间的路由选择协议,比较关注经济策略和政治策略
外部网关协议只有一个,就是 BGP 边界网关协议。BGP协议将因特网中数以前千计的ISP连接起来,基于DV算法。
BGP协议中,每个AS有一个连接其他AS的网关,这个网关既参与内部网关的运算,又参与外部网关的运算。该网关将自身AS中的每一个设备进行路由聚集,通报给其他AS中的网关。其他网关收到消息后,发送给这个自治区内部的所有路由器
BGP在 DV 算法的基础上增加了一个 AS-PATH 字段,这个字段包含了已经走过的AS,用于进行环路检测。
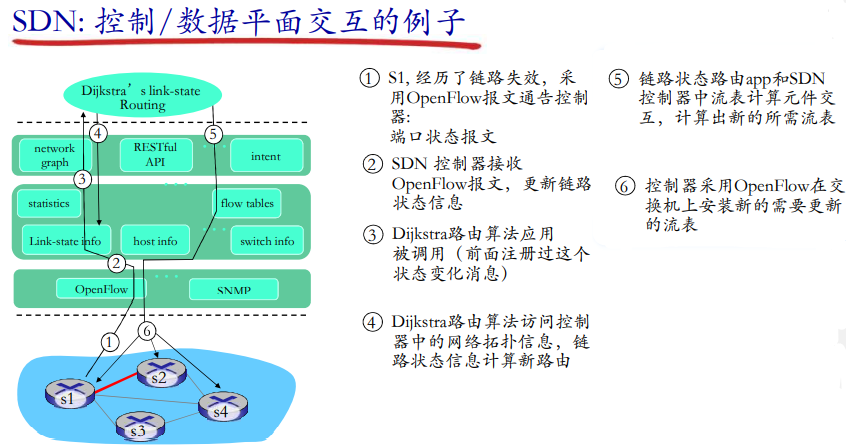
SDN控制平面
关键特征:
- 数据平面与控制平面分离
- 基于流的 匹配 + 行动模式
- 控制平面功能在数据交换设备外实现
- 网络可编程
ICMP协议
作用:主机和路由器之间沟通网络层消息。常见的消息有差错报告(404这些的)
链路层
链路层提供端到端的通信
网络层相当于是从 武汉 到 宁波,链路层相当于是其中的 公交车-高铁-公交车-走路 其中一段。
链路有两种类型的信道,一种是点到点的广播式的信道(多点连接),另外一种是多点连接的通信链路
多点连接的方式适合于局域网,点到点的连接方式适合于广域网
链路层在主机和路由器上的网卡实现
链路层提供服务
- 成帧(封装解封装)
- 链路访问控制
- 检错和纠错
- 相邻节点进行可靠数据传输
- 流量控制:使发送方和接收方的速度匹配
- 全双工和半双工服务
以上是一般化的链路层服务,对电缆等一些本来就很可靠的链路就不需要可靠数据传输,像 WiFi 这样的需要。
差错检测和纠正
奇偶校验
发送方附加一个比特,使得整个数据比特1的个数和为偶数/奇数
还可以将数据分组,形成二维偶校验
校验和方法
将数据以 k 位为一组作为一个整数,然后把整个帧的所有整数加起来,用得到的和作为差错检测比特。
CRC(循环冗余检测)
这个比较重要,CRC主要应用到了异或。发送方的帧给接收方后要恰好被能被 $G$ 整除
$D$ 表示要发送的数据比特,$R$ 表示跟在 $D$ 后面的 $r$ 位CRC 比特。国际标准规定了 $G$ 的值。
因此发送方只需要在原有的数据 $D$ 上增加
的比特位即可
1 | |
CRC 能检测数据比特小于 r + 1 位的差错,对大于 r + 1 位的有 $1-0.5^r$ 概率被检测到
多路访问协议
就是多点连接的协议,还有一种是单点访问协议,那个比较简单,就完成封装解封装和校验就可以了。多点访问主要需要解决的问题是冲突(多个点一起发送)。有 3 种方式
- 信道划分:将信道划分为时分、频分和码分
- 随机访问:允许冲突的产生,并且检测冲突。遇到冲突了就等待一会重新发送
- 轮流
信道划分协议
- TDMA
- FDMA
- CDMA
随机接入协议
CSMA/CD
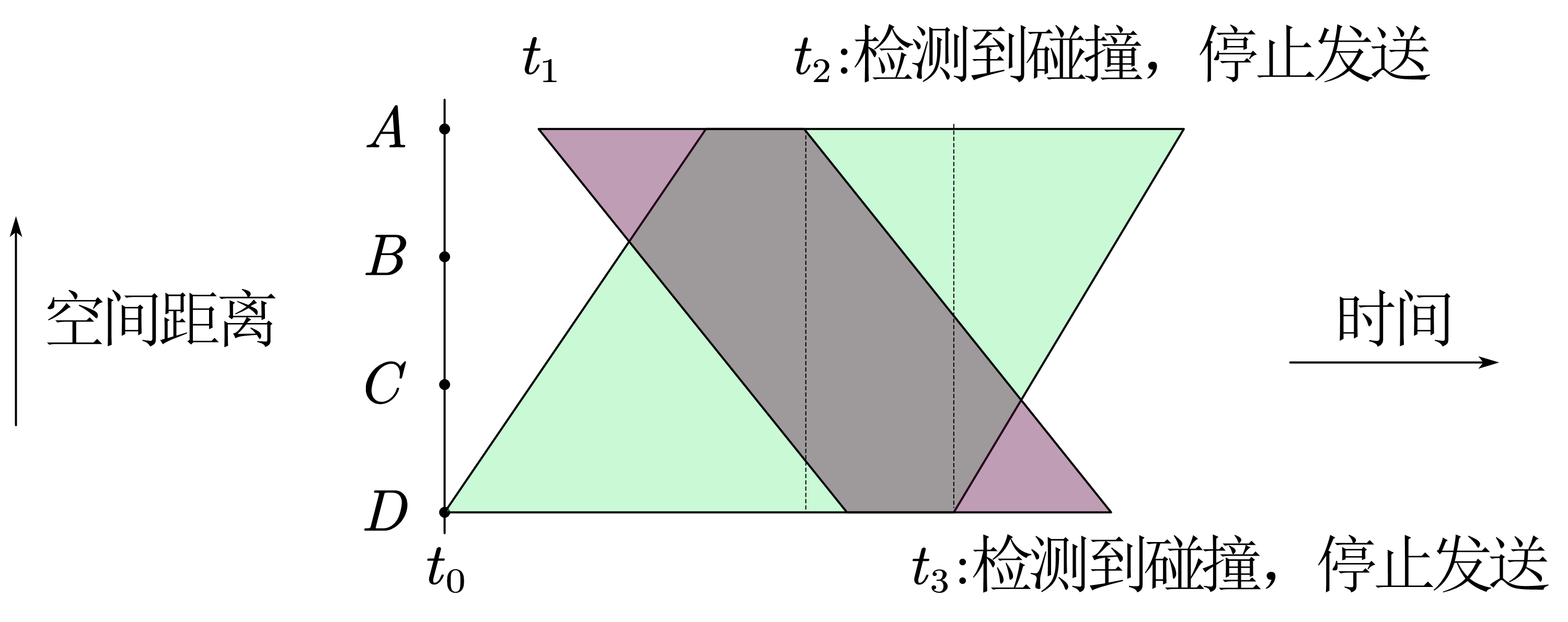
具有碰撞检测的载波监听多路访问(Carrier Sense Multiple Access with Collision Detection),用于局域网。
主要特点是
发送之前先监听(载波监听):如果此时链路中有一小段时间没有传输数据,才开始发送数据
如果于其他人在同时说话,则停止(碰撞检测):传输时一直监听信号,如果检测到另一个节点传输了干扰帧,就停止传输
中止传输后,发送方会随机的选择一个时间发送。这里采用 二进制指数退避 的方法进行:当此时连续发生了 $n$ 次碰撞,就在 $\{0,1,2,\cdots,2^n-1\}$ 中随机选择一个数设为等待时间
CSMA/CA
用于无线局域网。由于无线局域网有 信号强度随距离递减、有其他源的干扰、多路径传播 等特点,和有限局域网使用同样的逻辑就不太适用了。无线局域网还有隐藏终端和信号太弱无法检测的问题
无线局域网使用的是 带碰撞避免的CSMA/CA (CSMA with Collision Avoidance)
- 当发送方检测到信道空闲时,发送方会等待一个短时间后,进行发送,无论是否冲突把帧一次性发完。发送完毕后等待接收方的确认。
- 收到确认:如果要发下一帧,执行下面的操作(发送方检测到信道正在传输时对应的操作)
- 没收到确认:执行下面的操作(发送方检测到信道正在传输时对应的操作)
- 当发送方检测到信道正在传输时,发送方会选择一个随机的等待时间,信道空闲的时候等待时间递减。当等待时间减少到 0 时,发送整个数据帧
CSMA/CA 还有一个可选项:就是遇到大文件要传输时,先发送一个很短的 RTS 帧。接收方收到后向其邻居发送 CTS 帧。发送方收到后等一段时间开始发送,接收方的邻居收到后延迟发送。
轮流协议
- 令牌传递协议