CPU、操作系统和网络中的流水线
流水线在优化效率中特别常见,这里就对比一下这三块中用到的方法,把他们串起来
从最底层的CPU,再到操作系统,最后到网络一层层向上
CPU中的流水线
CPU中,一条指令的执行可以分为 取指、译码、执行、访存、写回和PC更新 6个阶段,当执行到某一阶段时,其他电路就会停下来等待,这样就造成了资源的浪费。因此采用流水线当一条指令还没执行完,就开始执行下一条指令。
取指(Fetch):CPU根据 PC 寄存器从内存中取出指令字节。并从字节中识别指令类型,判断是否含有寄存器指示符、常数等,计算指令长度。
指令类型由
icode和ifun两个值表示译码(Decode):从寄存器文件读取数据
执行(Execute):ALU进行运算(有三种类型的运算:算术逻辑运算、有效地址的计算和
push,pop指令中栈的计算)访存(Memory):内存的读写
写回(Write back):将计算结果写回到寄存器中
PC更新:将PC设置为下一条指令的地址。当涉及到条件判断时,采用 分支预测 策略,先假定要执行其中一个。如果预测失败,在进行相应的回退
一条指令执行的 6 个部分不一定全部都执行
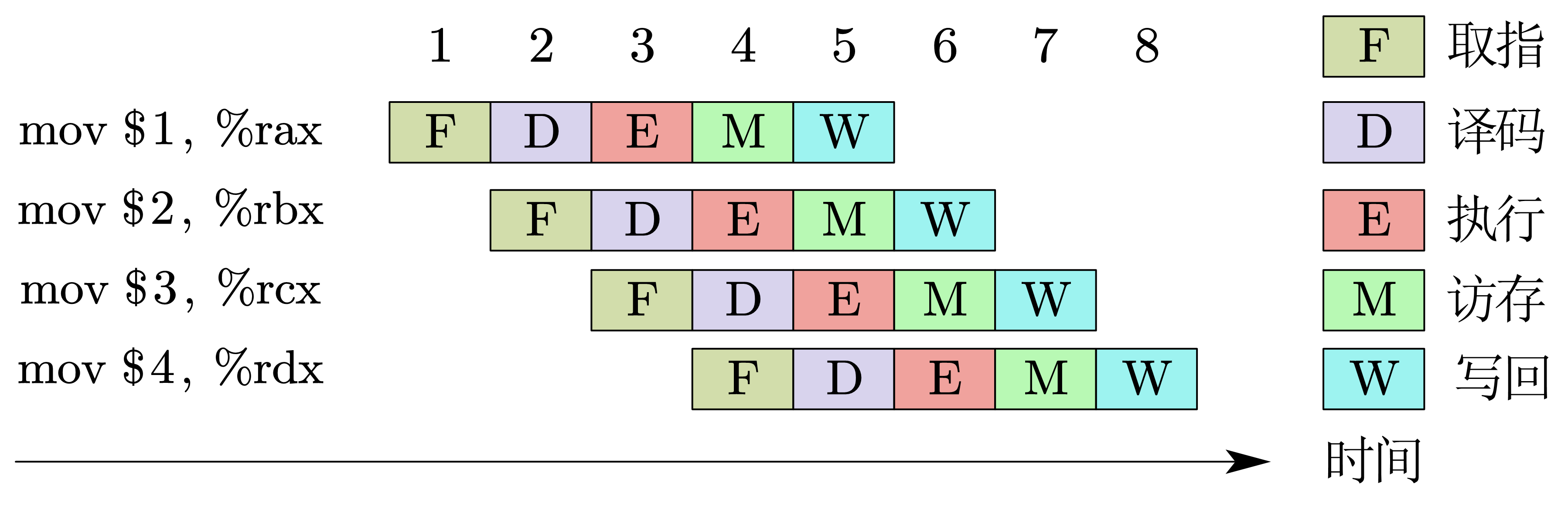
在第5个时刻,CPU的所有部件都运行起来了
引入流水线后,相邻指令之间就会出现一些问题,可以分为 2 类
- 数据冒险:当一条指令的执行需要用到正在运行的指令的结果,如果不进行处理,就会产生错误
- 控制冒险:当遇到
jmp,ret或调用这些指令时,需要计算下一个指令的地址,可能会出现错误
数据冒险
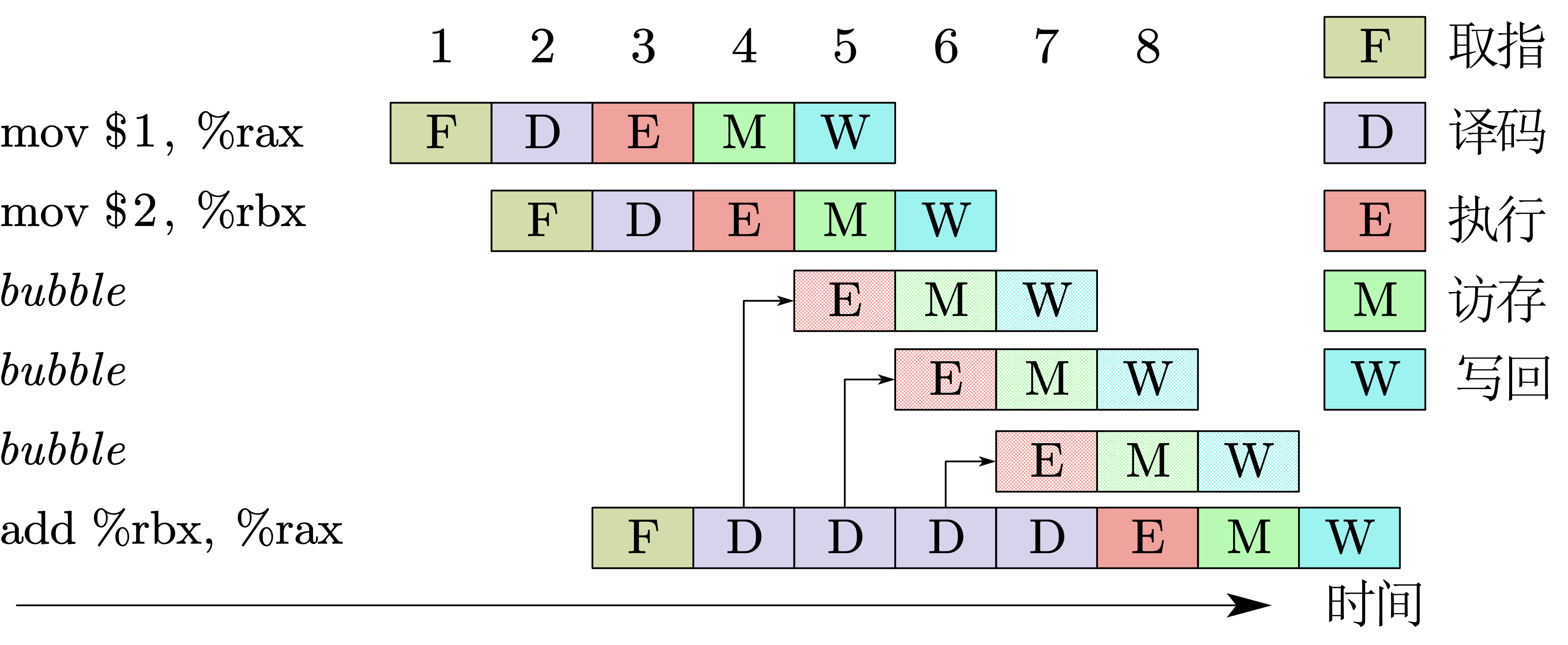
解决数据冒险最简单的策略就是 暂停,在各个阶段的电路中运行一段空的指令(气泡)。气泡不会改变寄存器和CPU的状态
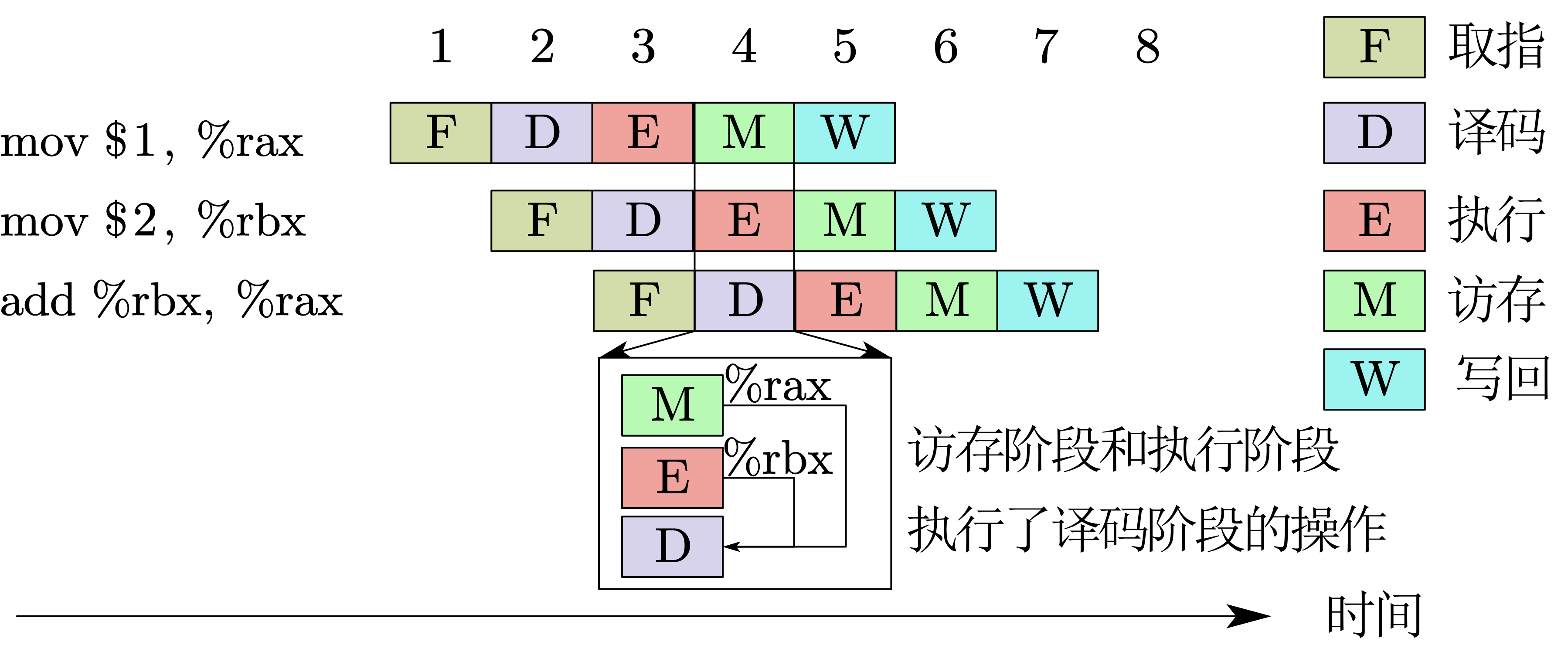
有些数据在写回阶段前就已经计算出了结果,因此为了提高效率,可以直接把执行阶段的计算结果 转发 给译码阶段
当然,有些指令到了后期才出结果,就算转发也会出现数据冒险(如
mov (%rbx), %rax),这时候就要 转发 + 暂停 结合使用
控制冒险
当执行 ret 指令时,下一条指令的地址在内存栈中,因此要在访存阶段才会得到下一条指令的地址。再就是 jmp 指令不好预测
对 ret 指令,就是通过暂停来解决控制冒险
对 jmp 指令,当发现预测错误,就立即停止正在执行的错误代码,然后向后面的阶段 插入气泡 ,重新执行正确的代码
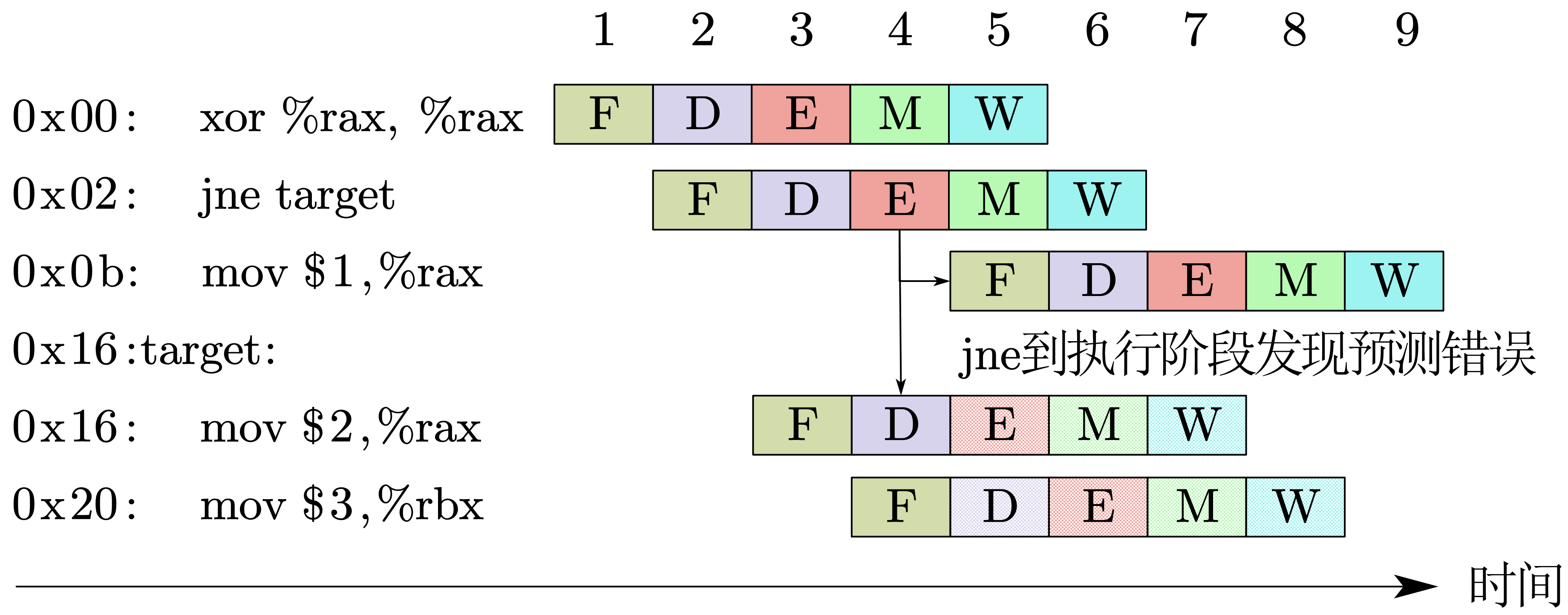
当然,执行的时候可能出现不止一个错误。采用暂停 + 插入气泡的方式解决
操作系统中的流水线
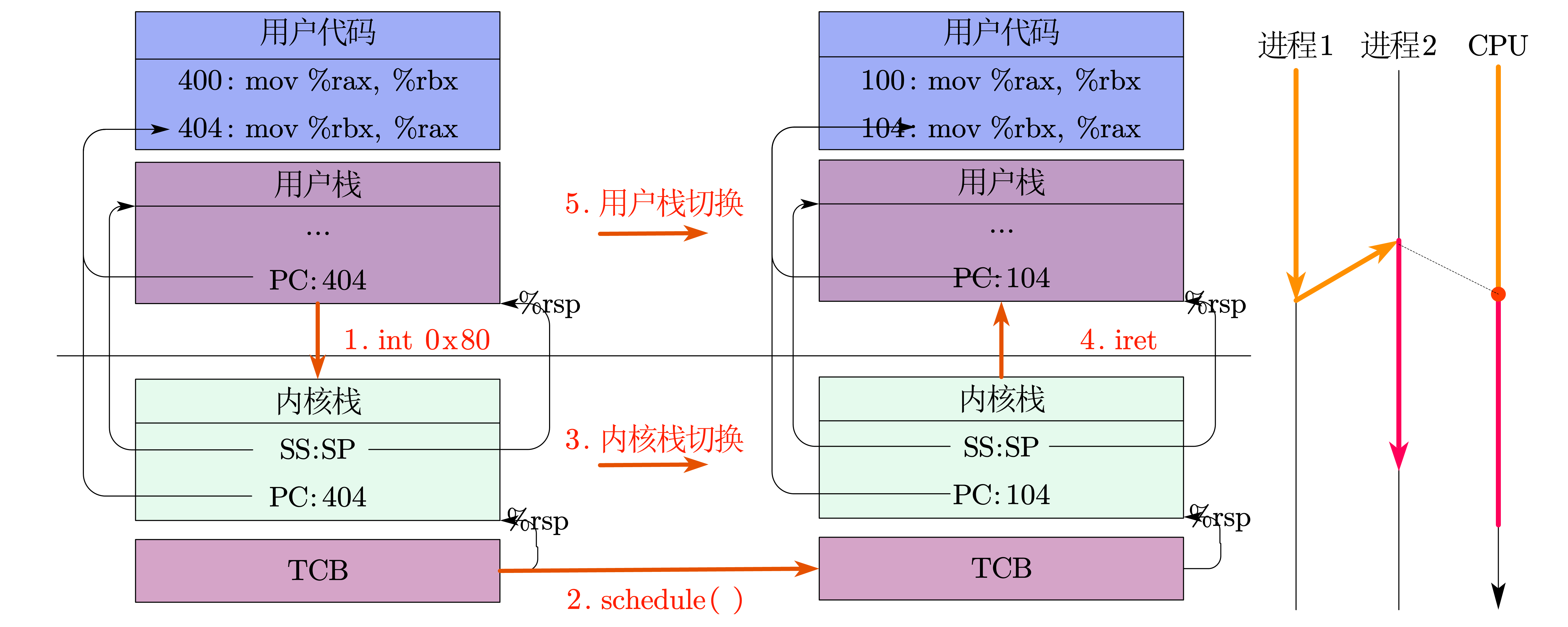
操作系统中的流水线主要就是CPU进程的切换。当进程因为 IO 或超时计时器到时了,操作系统就需要切换应用进程,保证CPU一直处于工作中。
和CPU中的流水线相比,操作系统麻烦的地方在于数据的保存。由于切换后需要恢复进程的上下文,同时,由于涉及到对操作系统核心的保护,操作系统的切换分成了 5 段
网络中的流水线
计算机网络中的流水线有两个地方
- 应用层 HTTP1.1 中采用持续性链接的 HTTP,在同一个 TCP 连接中,一个请求的响应还没接收就继续发送下一个请求
- 传输层中 TCP 连接发送报文段。设置发送缓冲区 > 1 以实现流水线发送,根据接收缓冲区的大小有两种流水方式,第一种是 GBN 协议,另外一种是 SR 协议
网络中的流水线不需要考虑到计算出错,也不需要考虑恢复状态,因此简单很多,只需要考虑差错恢复。
总结
由于不同的使用环境,导致流水线不同的关注重点。CPU要求执行不能出错,因此 CPU 流水线对相邻指令干扰的情况设置了暂停、气泡的方式;操作系统要求切换前后状态不变,因此操作系统流水线设置了 5 段以及映射表的切换,来实现切换前后进程的栈、PCB和内存是不变的;网络丢失了重发就可以,因此只需要考虑差错恢复,设置重发的规则即可。